AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
Attention is all we need - build a Multi-Head Attention from scratch

In this article, let’s take a look at another way of feature crossing - leveraging the most popular attention approach, aka Multi-Head Attention to catch the feature interactions.
Multi-Head Attention is the main block inside Transformer and it’s good at effectively learning feature correlations. Naturally here comes the idea of reusing the Multi-Head Attention to catch complex feature interactions
In the AutoInt paper, they propose a novel interacting layer which stacks multiple layers of Multi-Head Attention to form high-order feature interactions
An extra residual connection is added to the interacting layer which allows combining different orders of feature combinations
The attention mechanism for measuring the correlations between features offers good model explainability. This is a big advantage compared to other models like DCN and DeepFM. And it’s also a good tool for feature importance analysis
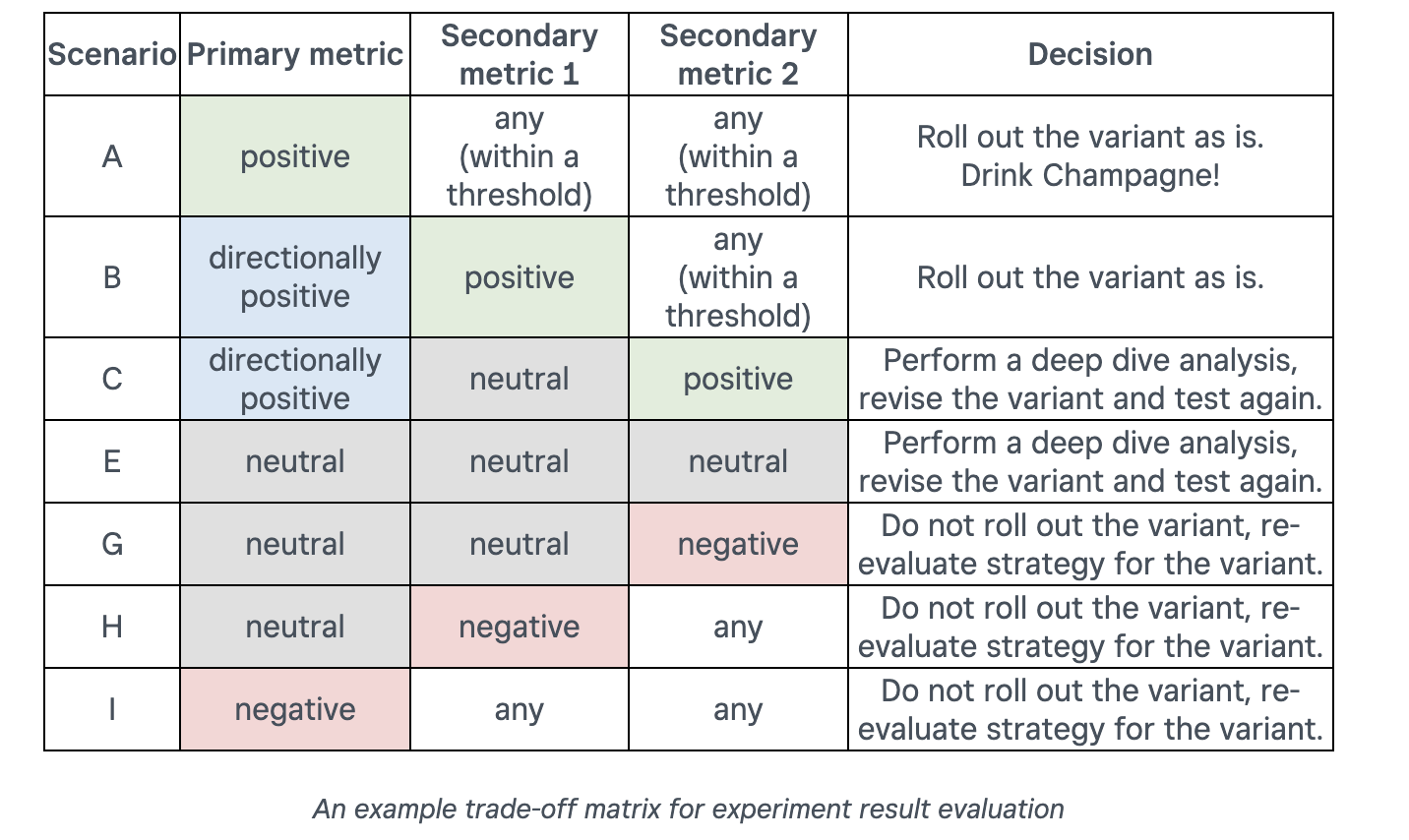
Model Overview
The general picture of the model is shown below. It consists of 3 parts:
The first part is the embedding layer. For sparse features, they use a common embedding mapping table. For dense features, they also transformed them into embeddings. Details will be shared in the next section
The second part is the major contribution of this paper. A Multi-Head Attention module is combined with a residual connection to catch feature interactions
The last part is similar to all other papers, all the output embeddings are concatenated and feed a to dense layer with sigmoid activation for binary prediction
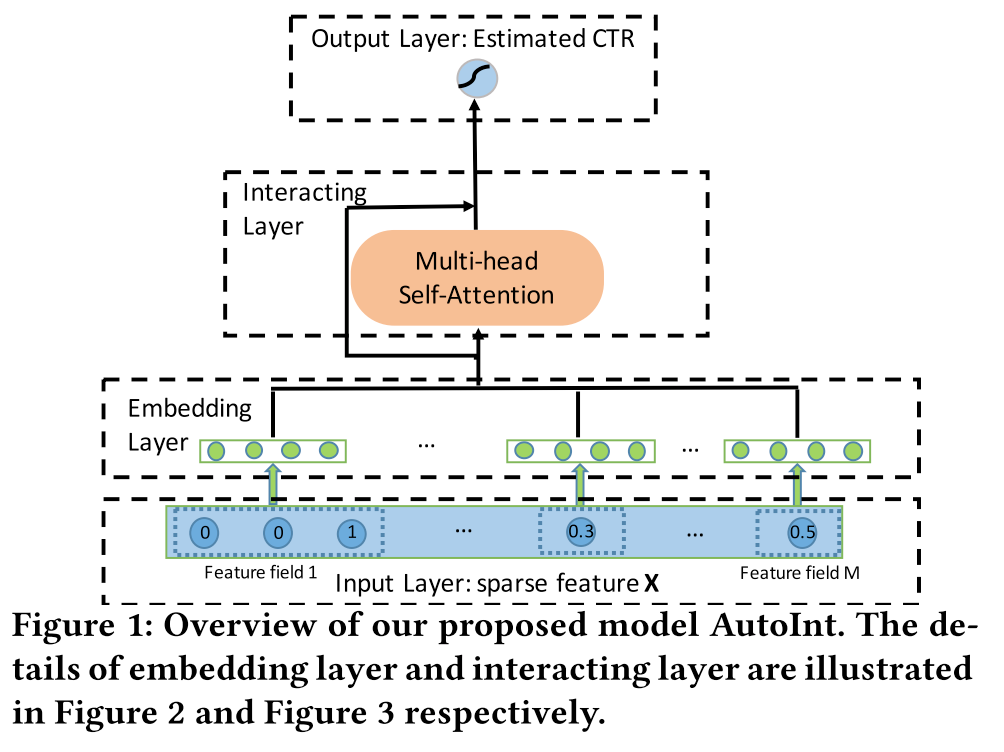
Embedding Layer
For sparse features, there are two cases:
One-value features are transformed into embedding vectors directly
For multi-valued features, like movie genres which can have multiple values, an average pooling operation is applied to all the embedding vectors
For dense features, in practice, there are there methods to handle them:
Normalize and directly concatenate with other embedding features. This is the most common method
Discretize and transform them into categorical features, then turn them into embedding vectors. This method provides a higher capacity for feature interactions and better explainability. After transforming to embedding vectors, we can apply any kind of feature interaction directly on them. As far as I know, TikTok are using this approach
Represent the dense features also as embeddings and use the feature value as the weight of the embeddings. In this paper, they choose this approach. In the equation, Vm is an embedding vector for field m, and Xm is a scalar value
\(e_m = v_mx_m\)
Which method is better? I didn’t find a solid answer yet. Personally, I prefer the second method because of the capacity and explainability it brings.
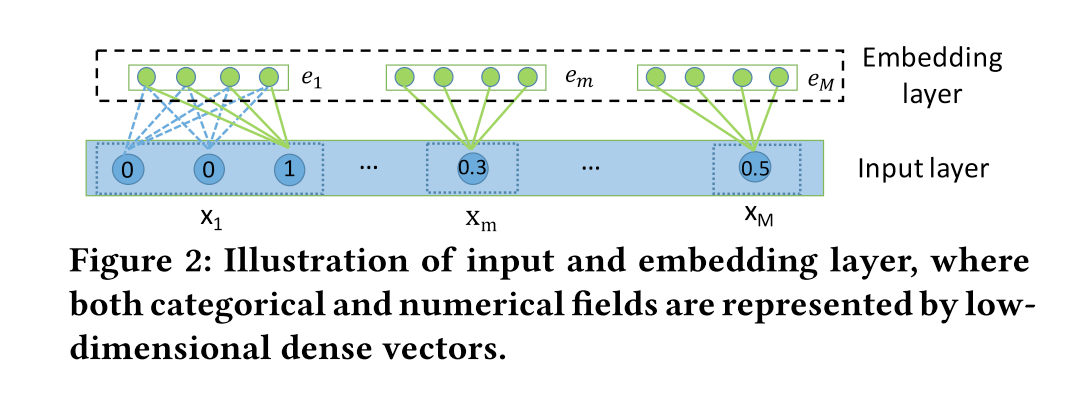
Interacting Layer
The interacting layer is a variant of Multi-Head Attention. Recall the structure of Multi-Head Attention.

In the interacting layer, most parts are kept the same, the only difference is there is no linear projection layer on the output.
As shown in the picture, here α is the attention weight and e is the embedding vector.
Then, all the head vectors are further concatenated as the output for field m.
Finally, they put a simple Relu activation function after the residual connection to preserve previously learned combinatorial features. Recall the X0 - the input of the first layer in DCN, this is actually a similar idea.
Build the Attention Layer
Actually, TensorFlow already provides the Multi-Head Attention layer. But let’s build it from scratch, here is the link. This is a good coding practice and interview question.
First, we have Q, K, and V three projection weights and the dimension is the head_dimension * head_num.

Then we apply the projection weights to input features

Split and reshape all the there tensors, the main purpose here is to separate the head tensors from each other. We can also use reshape like this, to achieve the same result, but I think split and stack are clearer.

The next step is to calculate the attention score. Apply matrix multiplication on each field tensor, scale, and apply a softmax function. Then finally, use a softmax function on the last dimension to acquire the corresponding scores.

The last step is to restore the original shape, notice that the split operation will introduce an extra 1-size dimension. We need to squeeze it.
And finally, a residual connection can be chosen to add.

We can stack multiple attention layers together and integrate them with linear and DNN layers. This is the same as the DeepFM and XDeepFM model structures.

Experiments
Run a quick experiment on MovieLens-1M. One interesting thing here is without DNN layers, the performance is a bit better. I think this is because the MovieLens task is too simple, the Interacting Layer itself can finish the job.
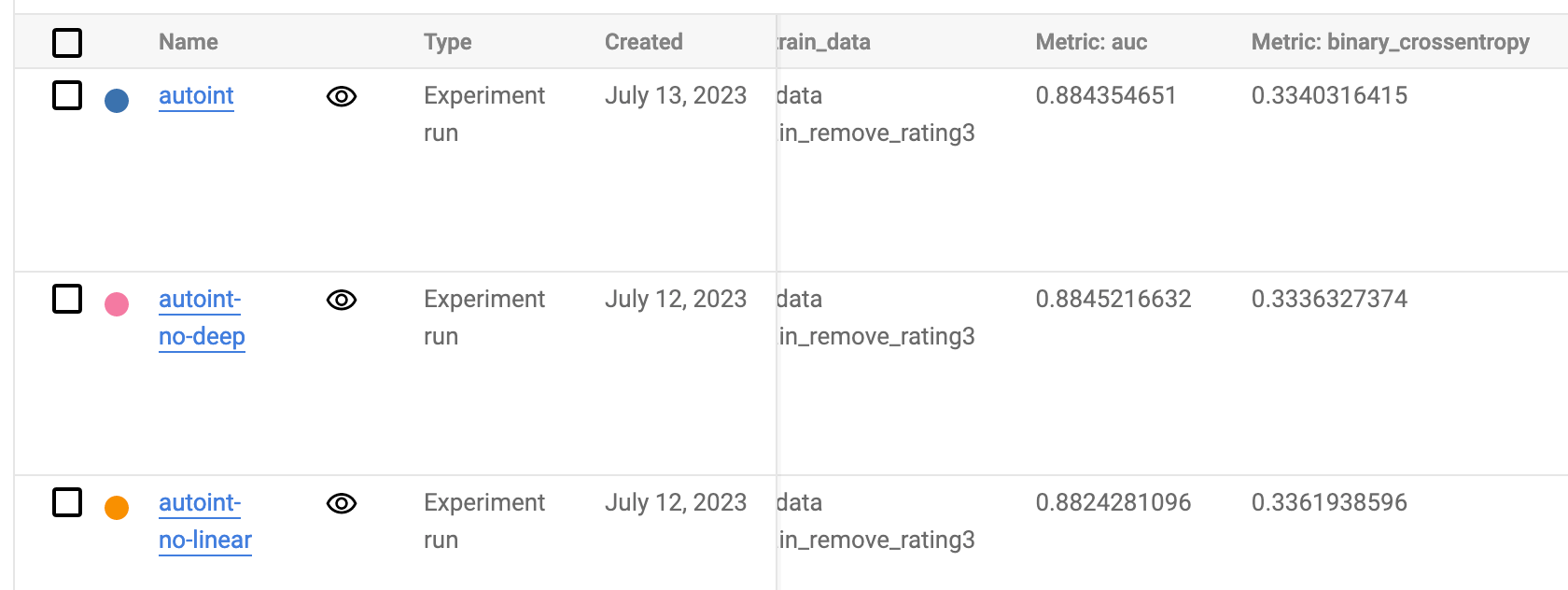
Another good thing about AutoInt is it has fewer parameters than XDeepFM. In the paper, these two models show the highest performance. And AutoInt model trains much faster than xDeepFM.
Explainability
I verified the attention scores in the interacting layer. We can see some interesting results:
With user_id and movie_id embedding features, the most higher scores are from the interactions of <user_gender, movie_id> and <user_age, movie_id>. The movie title and genres show a similar trend. This means movie_id is the strongest feature and the model memorizes it well
We also see that the time-relevant features like day_of_week and hour_of_day are also important
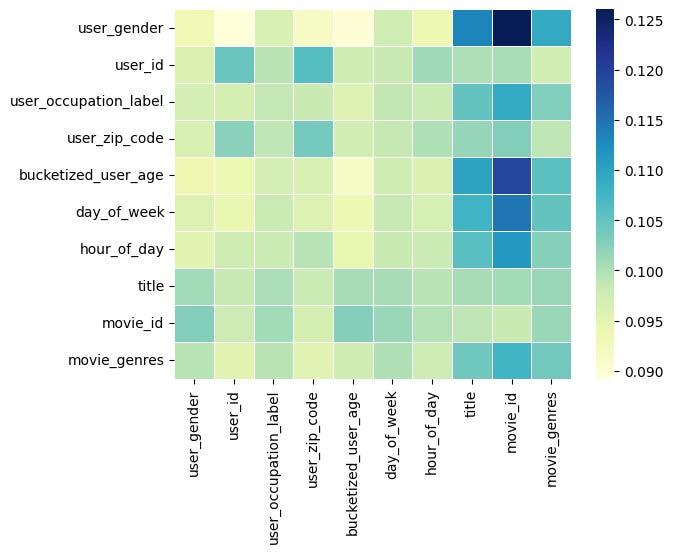
with user_id and movie_id Without user_id and movie_id, we can see that the movie title becomes the most important feature, and all the interactions are transferred to the title. This means the model learned the information from title embeddings


That’s all about the AutoInt model. In practice, I prefer to use it other than xDeepFM because of its good explainability.
Weekly Digest
Every week, I will collect articles that I think are worth reading and list them here.
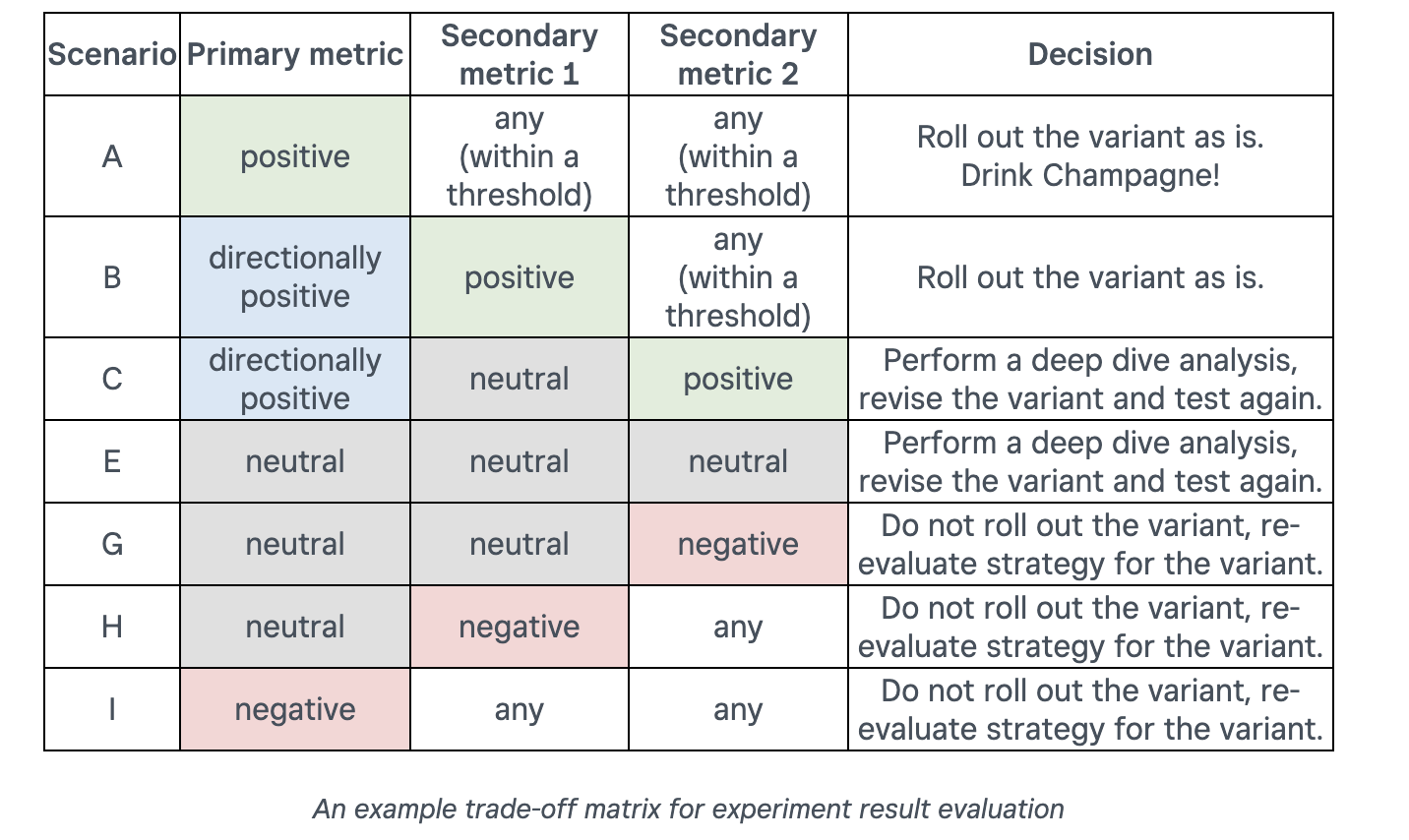
Lessons Learned From Running Web Experiments. Unveiling key strategies & frameworks from square
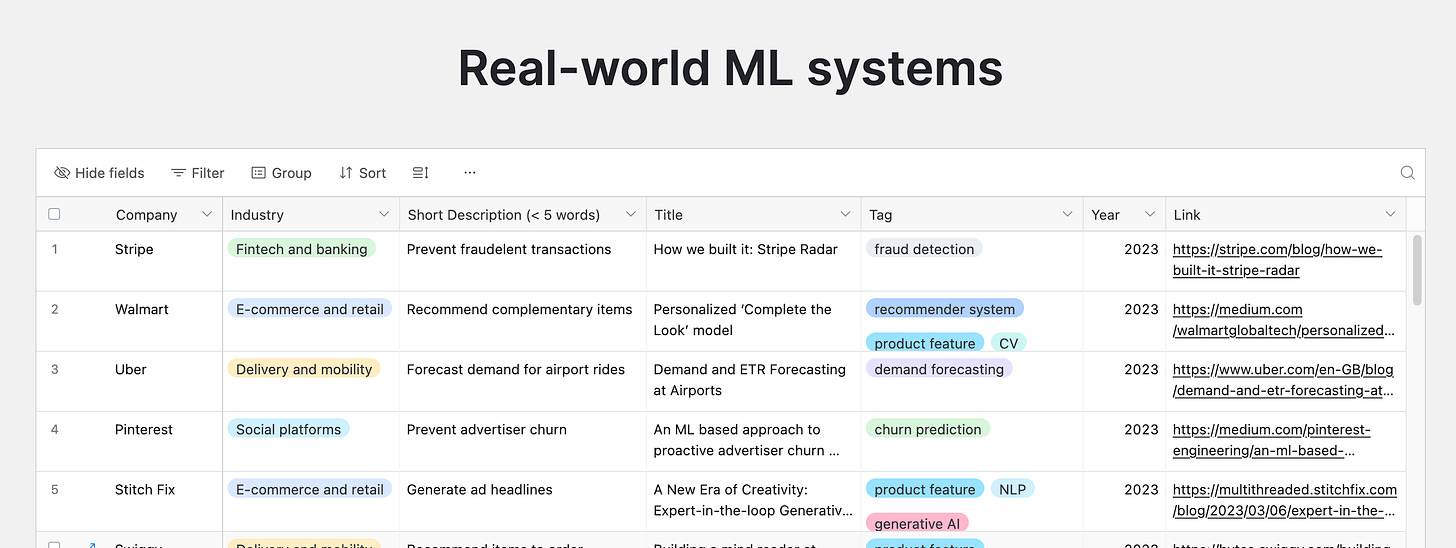
ML system design: 200 case studies to learn from, an amazing collection of ML system designs
The 5 core principles of life | Nobel Prize-winner Paul Nurse, what is life?
Ask HN: Are people in tech inside an AI echo chamber? Every "AI" related business idea I've seen prop up recently is people just hooking up a textbox to ChatGPT's API and pretending they're doing something novel or impressive, presumably to cash in on VC money ASAP
How Memory Safety Approaches Speed Up and Slow Down Development Velocity? Development velocity is the most important thing to optimize for. It doesn't matter how perfect your code is if it doesn't make it into the hands of the players in time
The Harried Leisure Class. Rising productivity decreases the demand for commodities whose consumption is expensive in time