

SASRec: Self-Attentive Sequential Recommendation
SASRec: Self-Attentive Sequential Recommendation
When Transformer meets sequential recommendation

Today, let's explore one of the classic sequential recommendation models, SASRec1. During my attendance at RecSys 2022, SASRec and Bert4Rec were the models that received the most attention and discussion at the conference. Therefore, delving into the specifics of these models is certainly worthwhile. Fortunately, given our existing knowledge of Transformers, grasping SASRec shouldn't be too challenging.
Moving forward, I'll experiment with a new post format. For straightforward models like SASRec, I'll aim to provide a concise explanation, focusing on the key concepts and omitting the more intricate details found in the research paper.
Sequential Recommendation
Sequential recommendation, as previously explained, is a recommendation system that tailors suggestions to users by considering the sequence and order of their past interactions or actions. In this context, SASRec (Self-Attentive Sequential Recommendation) is a classic model used for sequential recommendation.
As shown in the SASRec picture below, in the typical SASRec architecture, the input consists of a user's historical behavior sequence. The goal is to predict the next item the user is likely to interact with. This prediction task involves taking the original input sequence and shifting it by one step to the right, effectively predicting the user's next action in the sequence.

Sequential vs. General Recommendation Model
A commonly asked question when it comes to sequential recommendation models is whether they can outperform general recommendation models like DCN or MaskNet. In my experience, the answer to this question depends on your specific business scenario and the nature of your data.
Here's a general guideline to consider:
Sequential Models for Strong and Explicit Label Signals: If your recommendation task relies on strong and explicit label signals such as conversion (e.g., making a purchase) or direct user actions like buying, sequential recommendation models like SASRec or recurrent neural networks (RNNs) may be a better choice. These models are designed to capture the sequential patterns in user behavior data and can excel when predicting explicit user actions.
General Models for Implicit Label Signals: On the other hand, if your label signals are more implicit and less straightforward, such as clicks, reads, or interactions that don't directly lead to purchases, then general recommendation models like DCN or MaskNet might be a more suitable choice. In such cases, you can still leverage the user behavior sequence as an important feature in your input data for these general models
SASRec Illustration
Let's break down the main components of the SASRec (Self-Attentive Sequential Recommendation) model, moving from bottom to top:
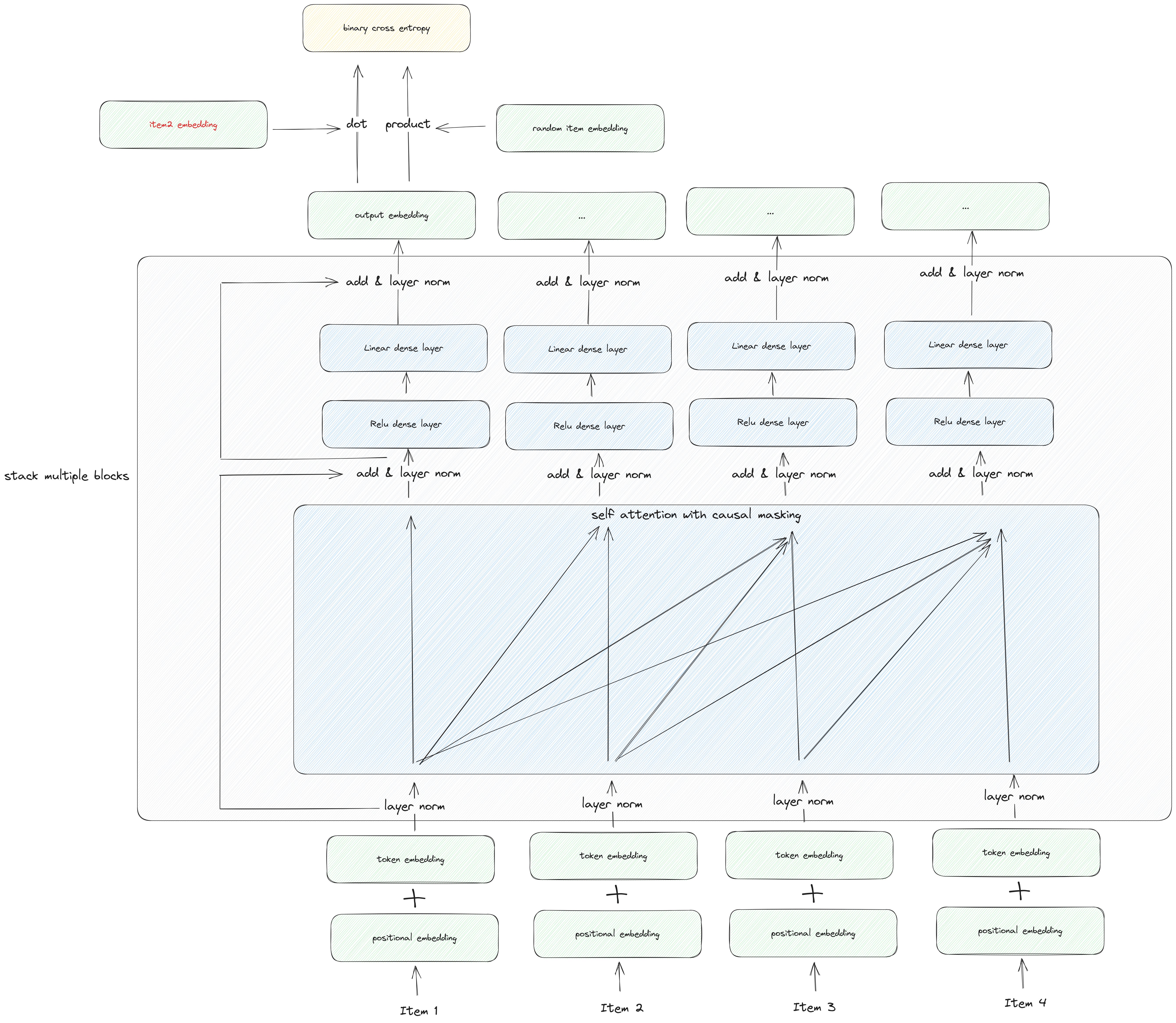
Input Data - User Sequence: At the bottom of the model, you have the user sequence, which is organized based on timestamps. This sequence represents the historical actions or interactions of the user.
Embedding Layer: The input sequence goes through an embedding layer, which consists of two parts:
Positional Embedding: This component encodes the position or order of each item in the sequence. It helps the model understand the temporal aspect of the interactions.
Token Embedding: Token embeddings represent the items or actions themselves in the sequence. These embeddings are similar to what you find in BERT models, excluding the segment embeddings used in BERT.
Layer Normalization: A layer normalization step is inserted between the input embedding and subsequent layers. Layer normalization helps stabilize and speed up training by normalizing the input data.
Self-Attention and Feed-Forward Layers: The input embedding, after layer normalization, is processed through a stack of multiple self-attention and feed-forward layers. Here's the order of processing:
Self-Attention Layer: This layer captures dependencies between different positions in the sequence. It uses self-attention mechanisms to weigh the importance of items in the sequence while considering their relationships.
Point-wise Feed-Forward Layers: After self-attention, the output is passed through two point-wise feed-forward layers. "Point-wise" means that the layer weights are shared across positions in the sequence. These layers allow the model to capture complex patterns within the data.
Causal Mask: Within the self-attention layer, a causal mask is applied. This mask is used to ensure that the model does not have access to information from future positions in the sequence. It prevents "information leakage" from upcoming interactions and helps the model make predictions solely based on past interactions, mimicking the real-world sequential nature of user behavior.
Prediction Layer: In the prediction layer, the output embeddings are used to generate recommendations. Specifically:
Dot Product with Samples: Each output embedding is dot-producted with two samples:
Positive Sample: This is the next item in the user sequence, which serves as a positive example for the model.
Negative Sample: A negative sample is randomly selected from the entire corpus of items. This sample represents items the user did not interact with, and it helps the model learn to differentiate between positive and negative examples.
Loss Calculation: The positive logits (resulting from the dot product with the positive sample) and the negative logits (resulting from the dot product with the negative sample) are input into a binary cross-entropy loss function. This loss function quantifies how well the model is performing in distinguishing between positive and negative samples.
That’s the general picture of SASRec.
Implementation
I put an example code here for your reference.
Positional Embedding
This represents a simple addition of two embedding layers, closely resembling the structure of Bert embeddings.

Self-attention and Feed-forward
The key component, which I've termed the SASRecBlock, comprises both the self-attention and feed-forward layers. It's worth noting that the placement of dropout, residual connections, and layer normalization differs from the positions in a traditional Transformer, although this distinction is considered a minor detail based on their practical implementation.

Main Model
Let's now assemble all the components to create a SASRec model. It's important to highlight that the token embedding layer is shared among the input, positive samples, and negative samples.
To produce the final logits, we calculate the dot product between the output embedding and both the positive and negative embeddings.

Train
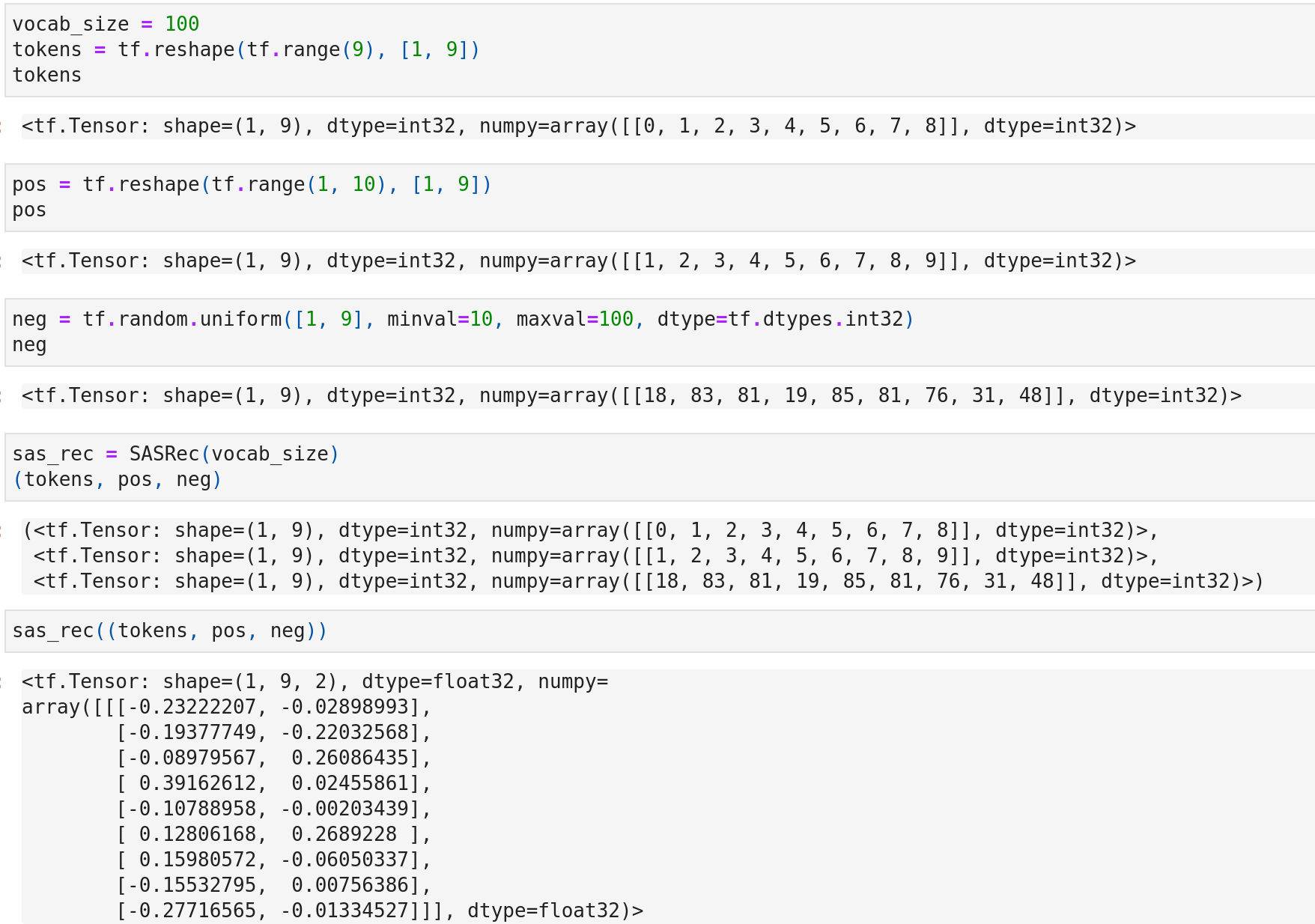
To facilitate a better understanding of the input and output structure, I've created three mock training samples.
In these samples, the positive items correspond to the input items shifted one position to the right in the sequence. On the other hand, the negative items are randomly sampled from the entire corpus.
Then define the loss and AUC metric functions according to the code provided by the author.

For a sanity check, let's train the model using the mock data. In this data, the labels are consistently represented as pairs of [1, 0], corresponding to the positive and negative sample positions.

That's all for SASRec. I believe that after we've thoroughly understood the Transformer and BERT models, comprehending the SASRec model is a piece of cake.😆
https://arxiv.org/pdf/1808.09781.pdf