
DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems
How google upgrade and improve the expressiveness of Cross Network?

In this post, let’s continue the paper-reading journey on feature-crossing. DCN-V21 is the upgraded version of DCN-V1. For DCN-V1, please refer to my previous post:

DCN-V2 refactors the Cross Network component and proposes a novel way of modeling feature interactions using a weight matrix and residual connection
It further introduces a low-rank version of Cross Network - decomposing the weight matrix into the multiplication of 2 smaller matrices. This approach can achieve comparable performance with a higher training speed
Inspired by the idea from Mixture-of-Experts (MoE), DCN-V2 also introduces another version of Cross Network - leveraging multiple experts to learn feature interactions in different subspaces and combining the learned crosses using a gating mechanism that depends on the input
DCN-V2 is proven capable of catching both feature-wise and bit-wise feature interactions effectively. Meanwhile, DCN-V1 can only catch bit-wise interaction which is blamed in the xDeepFM paper
DCN-V2 proposes 2 kinds of structures, stacked and parallel. They both show good performance in real-world experiments
Looks complicated? Take it easy. Let’s divide and conquer. I will provide concrete examples and code in this post.
Paper Reading
Overall Architecture
Let’s look at the general picture first.
As I mentioned above, there are stacked and parallel structures
In the stacked structure, the DNN layers are put after the Cross Network and the output of the Cross Network is fed into the DNN layers
In the parallel structure, the input is fed into the Cross Network and DNN layers simultaneously and the output of the Cross Network is concatenated with the output of the DNN layers
For the input, the sparse features are mapped into embeddings and concatenated with dense features

Cross Network V2
The core of DCN-V2 is the upgraded version of Cross Network. Let’s take a closer look and make a direct comparison with Cross Network V1.
The general structure is similar to the V1 version. In each layer, to create a higher-order interaction, the original input X0 interacts with the current input Xi
But there are 3 major differences here
The weight changes from a 1d vector to a 2d full matrix and the matrix multiplication order is reversed
The interaction operator between X0 and Xi changes to a Hadamard product
The bias is added before the multiplication operation


Feature interaction equation for Cross Network V2:
Feature interaction equation for Cross Network V1:
Let’s take a concrete example to understand the difference here.
Suppose we have the X0 as:
And here let’s ignore the bias for simplicity. For the V1 version, we have:
As we discussed in my previous DCN post, the issue here is although all the possible feature combinations have been constructed, the weights are the same across different feature pairs. This sets a hard constraint on the model capacity.
In the V2 version, we can construct the same feature interactions, but the weights are distinct from each other. This means we can learn different weights for different feature combinations. It’s the key to better expressiveness.
Cross Network Mixture of Low-Rank DCN
To further optimize the training cost and inference latency, they introduce the idea of decomposing the weight matrix with dimension d into 2 low-rank matrices with dimension r.
When 𝑟 ≤ 𝑑/2, the cost will be reduced
This indeed shares the same idea with Matrix Factorization (MF). They also mention that
They are most effective when the matrix shows a large gap in singular values or a fast spectrum decay
As we can see in the left picture, from their production model, the learned matrix does show a fast singular value decay.

So the original weight matrix can be approximated by 2 low-rank matrices U and V and their dimension r « d (original dimension of weight matrix).
There are 2 interpretations of this equation:
learn feature crosses in a subspace
project the input X to lower-dimensional r and then project it back to d
Interpretation 1 inspires them to adopt the idea from Mixture-of-Experts (MoE) as shown in the right part of the above picture. Here Gi(·) is the gating function, K is the total number of experts, and Ei(·) is the expert.
Interpretation 2 inspires them to leverage the low-dimensional nature of the projected space. They further apply nonlinear transformations in the projected space to refine the representation. 𝑔(·) represents any nonlinear activation function.
Experiments
They also spend quite some time proving that Cross Network V2 can learn any order of bit-wise and feature-wise feature interactions. This part is pure math, I will skip it here.
The remaining half of this paper is all about experiments. They conduct the experiments carefully and comprehensively. Here are some highlights and takeaways.
Cross Network V2 is much more efficient than plain DNN in fitting feature interactions.

Surprisingly, well-tuned DNN performed neck to neck with most baselines and even outperformed certain models.
This means with careful tuning, plain DNN is a very strong opponent compared to other core modules like FM in DeepFM, CIN in XDeepFM, and AutoInt.

For 2nd-order methods, DLRM performed inferiorly to DeepFM although they are both derived from FM. (DLRM is not a strong baseline)
DCN-Mix, the mixture of low-rank DCN efficiently utilized the memory and reduced the cost by 30% while maintaining the accuracy

Model Understanding
Whether the proposed approaches are indeed learning meaningful feature crosses?
They propose an interesting approach to explain the model - a block-wise view of the weight matrix.
This brings another way to understand the deep learning models 👏. Actually, the result below is similar to what I get from the Multi-Head Attention layer of AutoInt.


Show me the Code
TensorFlow Recommender (TFRS) library and DeepCTR all provide their implementation. But neither of them implements all the ideas in the paper and the gating function in DeepCTR is problematic. I will share all my 3 versions below.
The Cross Network V2 version without a low-rank matrix, is quite similar to the V1 version. We only need to replace the weight from a vector to a matrix and place the bias before feature crossing.

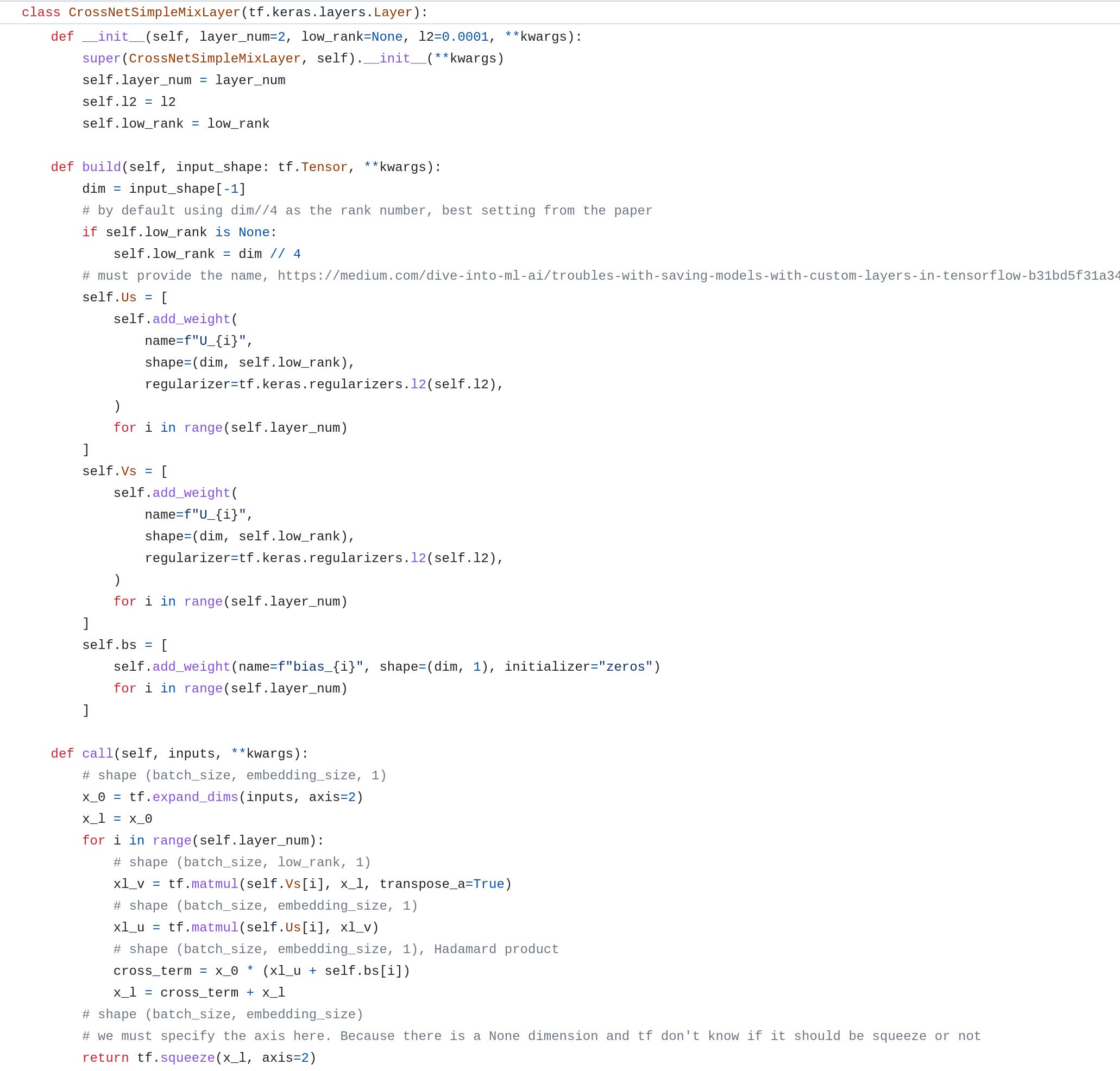
For the simple mix version, without gating and experts, we just follow the equation and multiply two low-rank matrices in order.
For the gating and multi-expert version, it’s a bit complicated. Here I support different activation and gating functions.
Iterate through all the layers, and initialize the array of experts and gating_scores for the current layer
Iterate through all the experts
Create and calculate the vectors for each expert
Apply the gating function to the input and get the gating score
Stack all the experts’ embeddings and gating scores, then weight the expert vectors using matrix multiplication

Weekly Digest
Optimized Deep Learning Pipelines: A Deep Dive into TFRecords and Protobufs (Part 1) and (Part 2), a good tutorial on how TFRecords and Protobuf work
Chronon — A Declarative Feature Engineering Framework. The feature store platform from Airbnb
Patterns for Building LLM-based Systems & Products, this post is about practical patterns for integrating large language models (LLMs) into systems and products
Building and operating a pretty big storage system called S3, how S3 works
443 KM | Finestrelles, Pyrenees – Pic Gaspard, Alps. The Longest Line of Sight


https://arxiv.org/pdf/2008.13535.pdf
thanks for this great post!
a correction: in section https://happystrongcoder.substack.com/i/135643135/cross-network-mixture-of-low-rank-dcn, there is no X_l in E_i(X_l).
another question:
`DCN-V2 is proven capable of catching both feature-wise and bit-wise feature interactions effectively. `
I understand bit-wise feature interactions. But don't get how this model is capable of feature-wise interactions. could you elaborate? thanks.