
A Gentle Introduction to BERT - Pre-training of Deep Bidirectional Transformers for Language Understanding
Welcome to the new era of NLP

In this post, let’s look at the famous BERT model - Bidirectional Encoder Representations from Transformers1. Since we already have a good understanding of the Transformer model, it will be easy for us to learn BERT. For your reference, the Transformer tutorial is listed below.


The major contributions of BERT are:
It shows the importance of bidirectional pre-training for language representations. BERT uses masked language models to enable pre-trained deep bidirectional representation
It proposes pre-trained representations to reduce the need for many heavily-engineered task-specific architectures. Now with a little bit of change in the input and output layer, it can easily adapt to various tasks
It successfully proves that the pre-train and fine-tuning framework is effective and advances the SOTA for eleven NLP tasks. Pre-train and fine-tuning become the facto standard for NLP tasks
Great strength produces miracles. Scaling to extreme model sizes also leads to large improvements on very small-scale tasks, provided that the model has been sufficiently pre-trained
The Overall Architecture
The architecture of the BERT model is really simple, it’s just a stack of Transformer encoders.
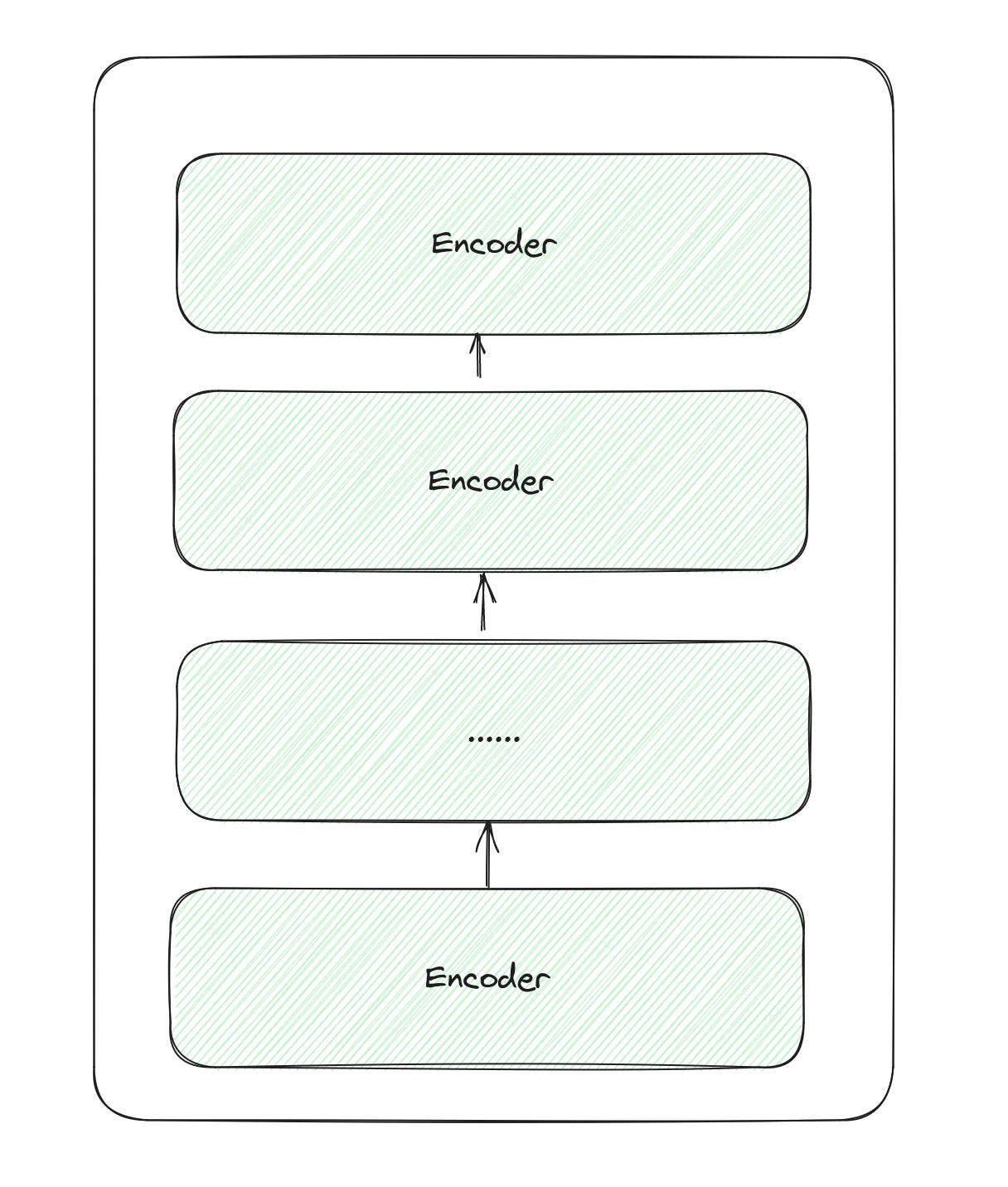
Why encoder?
This is because the encoder has a bidirectional self-attention, while the decoder only has a unidirectional self-attention with casual masking. In classification tasks like sentimental analysis or matching tasks like question-and-answer pairing, we have the whole context information, either looking from left to right or right to left is allowed and necessary. But in generative tasks that require creating new output according to the existing context, the inherent requirement is that we cannot look at future information. In this situation, the decoder is a natural choice, this is also the architecture of GPT models.
Let’s read an example code. You can view the tutorial here. I implemented a toy example of BERT's pre-training using Tensorflow to help us better understand the mechanism behind it. The whole implementation of BERT is complex and trivial, so I only build the basic modules. If you want to try BERT on a real-world problem, PyTorch and Hugging-Face are much better choices than TensorFlow.
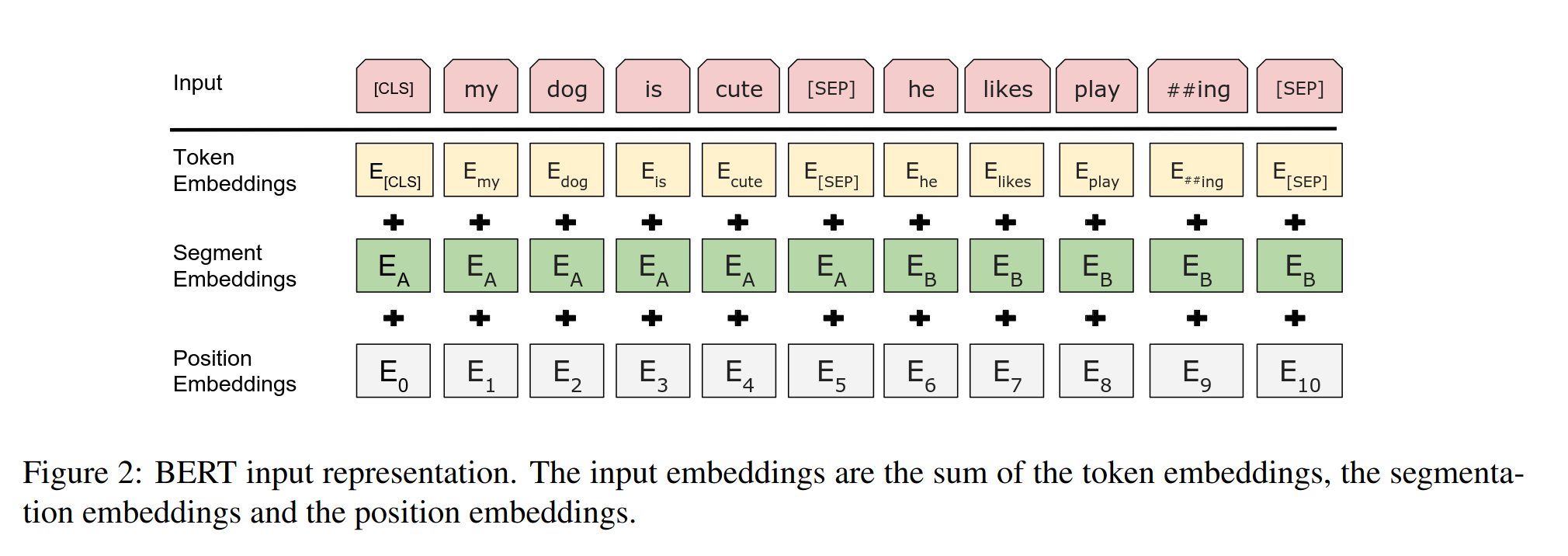
Input/Output Representations
To make BERT handle a variety of downstream tasks, the input representation is designed to easily represent either one sentence or a pair of sentences in one token sequence.
Here they use WordPiece embeddings other than word embeddings. WordPiece2 is a subword segmentation algorithm used in natural language processing. The vocabulary will be represented in subword segmentations instead of whole words so that the vocabulary size will be much smaller.
For example, "Sponge Bob Squarepants is an Avenger" will be split into:
[b'Sp', b'##onge'], [b'bob'], [b'Sq', b'##uare', b'##pants'], [b'is'],[b'an']
Here ## means the current segment can be concatenated with the previous segment to reproduce the original word.
Meanwhile, a special classification token ([CLS]) is inserted into the beginning of every sentence. The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks.
Sentence pairs are separated by a special token ([SEP]).
For example, "The man went to a grocery store. He bought a gallon of milk " will be turned into:
[CLS] the man went to a grocery store [SEP] he bought a gallon of milk [SEP]They also add a learned embedding to every token indicating whether it belongs to sentence A or sentence B.
Follow the tutorial from the TensorFlow blog, we can construct the input tokens for BERT.
input_word_ids means the token index for the token embedding table
input_mask is used for masking zero padding
input_type_ids represent the segments
The masked_lm_ids mean the original token index id
The masked_lm_positions mean the masked positions in the input_word_ids
The masked_lm_weights are the corresponding weights for the masked ids
These three mask inputs are used for the Masked LM pre-training task. More details will be shared later.

Here is an example code of the input embedding layer. The token embedding, segment embedding, and position embedding are added together as the final output. Since we already generate the masks in the input, here we just return the input_mask for downstream masking.
Pre-training
For the pre-training corpus, they used the BooksCorpus and English Wikipedia data to construct the input sentences.
Masked LM
Mask some percentage of the input tokens at random, and then predict those masked tokens. This procedure is called Masked LM. In BERT’s experiments, they mask 15% of all WordPiece tokens in each sequence at random.
But the downside is that there is a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. To mitigate this issue, they replace the i-th token with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time.
For example:
80% of the time, my dog is hairy → my dog is [MASK]
10% of the time, my dog is hairy → my dog is apple
10% of the time, my dog is hairy → my dog is hairy
The advantage of this procedure is that the Transformer encoder does not know which words it will be asked to predict or which have been replaced by random words, so it is forced to keep a distributional contextual representation of every input token.
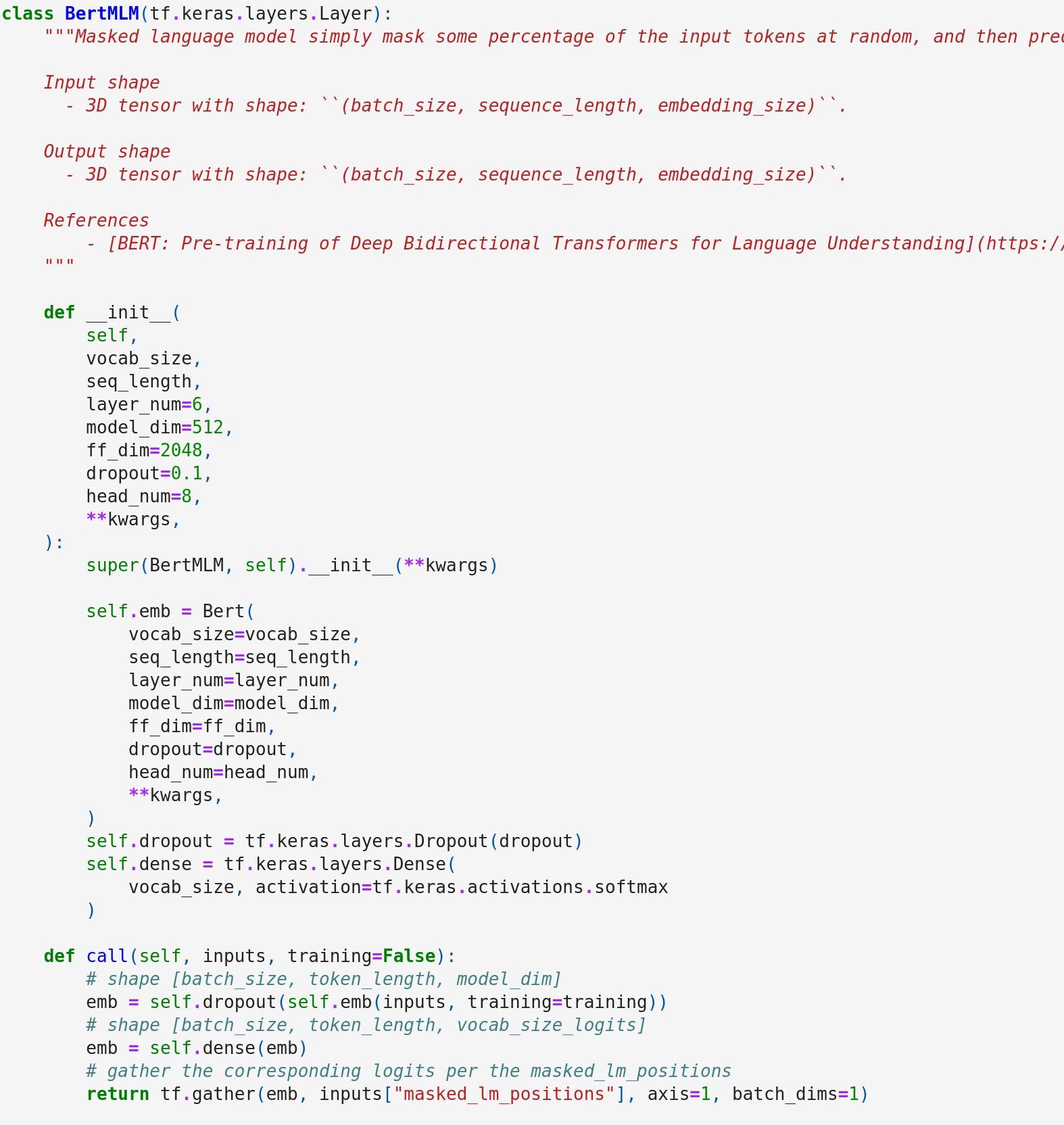
Here is an example code of the BERT Masked LM model. We can see that a dense layer is applied on the output of encoders and for each token we use softmax to get the probability distribution on the vocabulary. Then we gather the result on the masked positions and output the final logits.
Next Sentence Prediction (NSP)
LM task cannot catch the relationships between sentences. In order to train a model that understands sentence relationships, they pre-train for a binarized next-sentence prediction task that can be trivially generated from any monolingual corpus.
For example, 50% of the time the next sentence will be replaced by a random sentence.
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
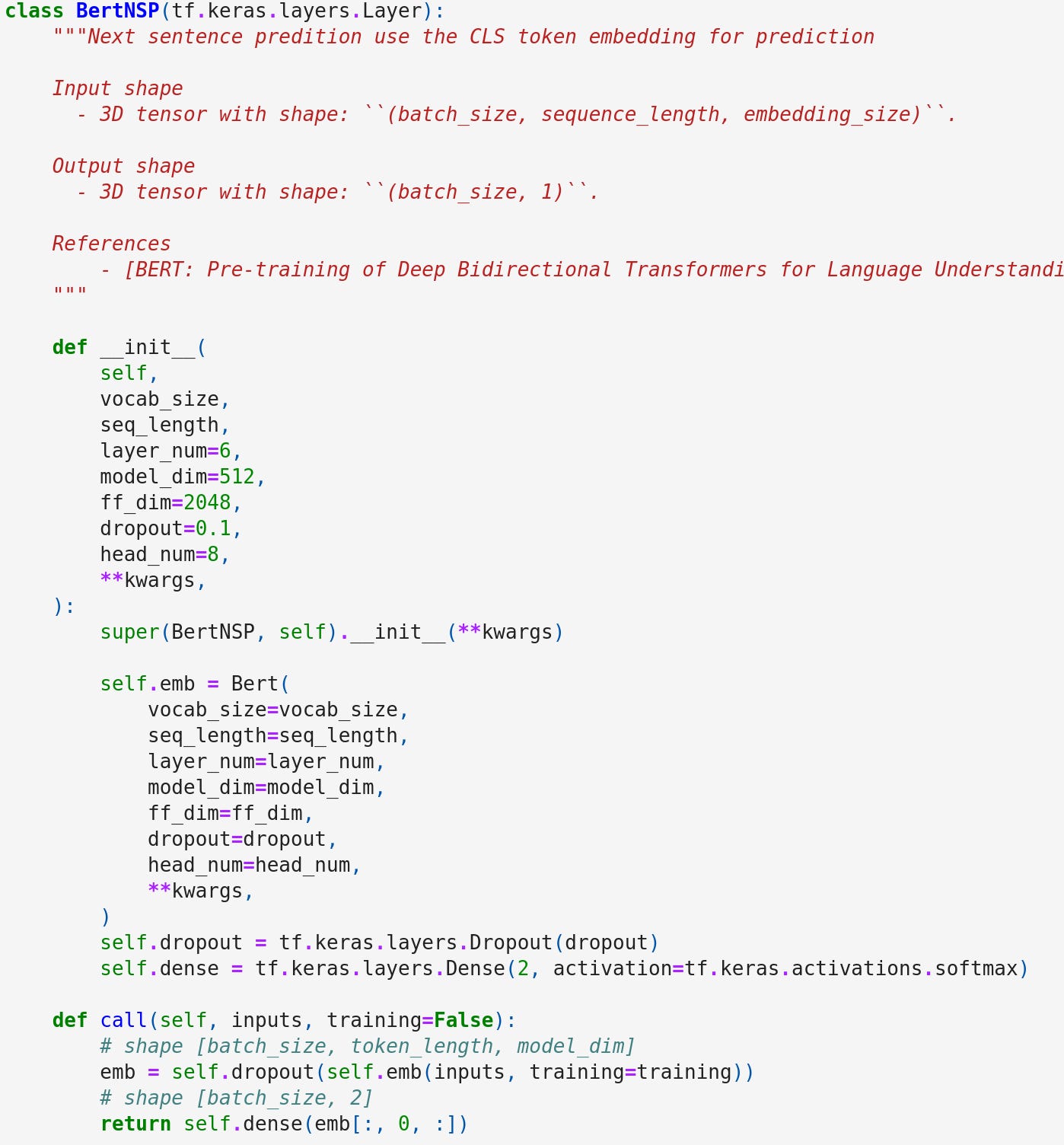
Label = NotNextAn example code. Notice that here we are using the first [CLS] embedding for binary classification. The rest is the same as the BERTMLM.
The output is like

Pre-train on Samples
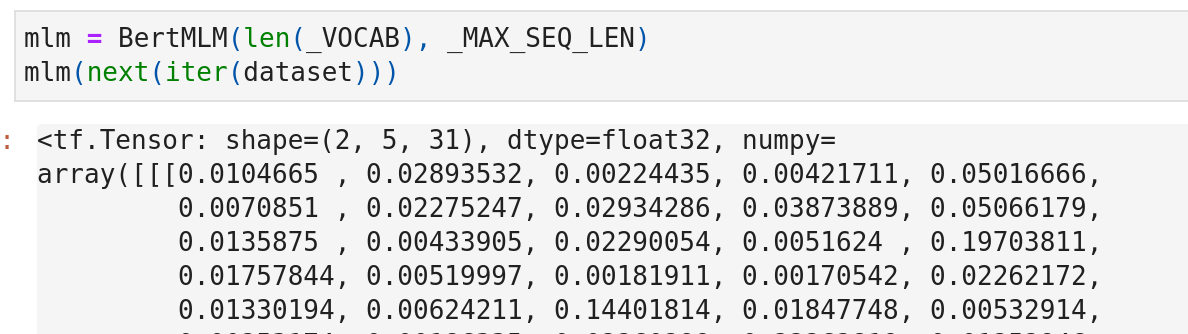
Let’s pre-train an example task on BERTMLM. Recall that our masked_lm_positions are
'masked_lm_positions': <tf.Tensor: shape=(2, 5), dtype=int64, numpy=
array([[1, 7, 0, 0, 0],
[6, 7, 0, 0, 0]])>,After gathering, the output of BERTMLM is like:
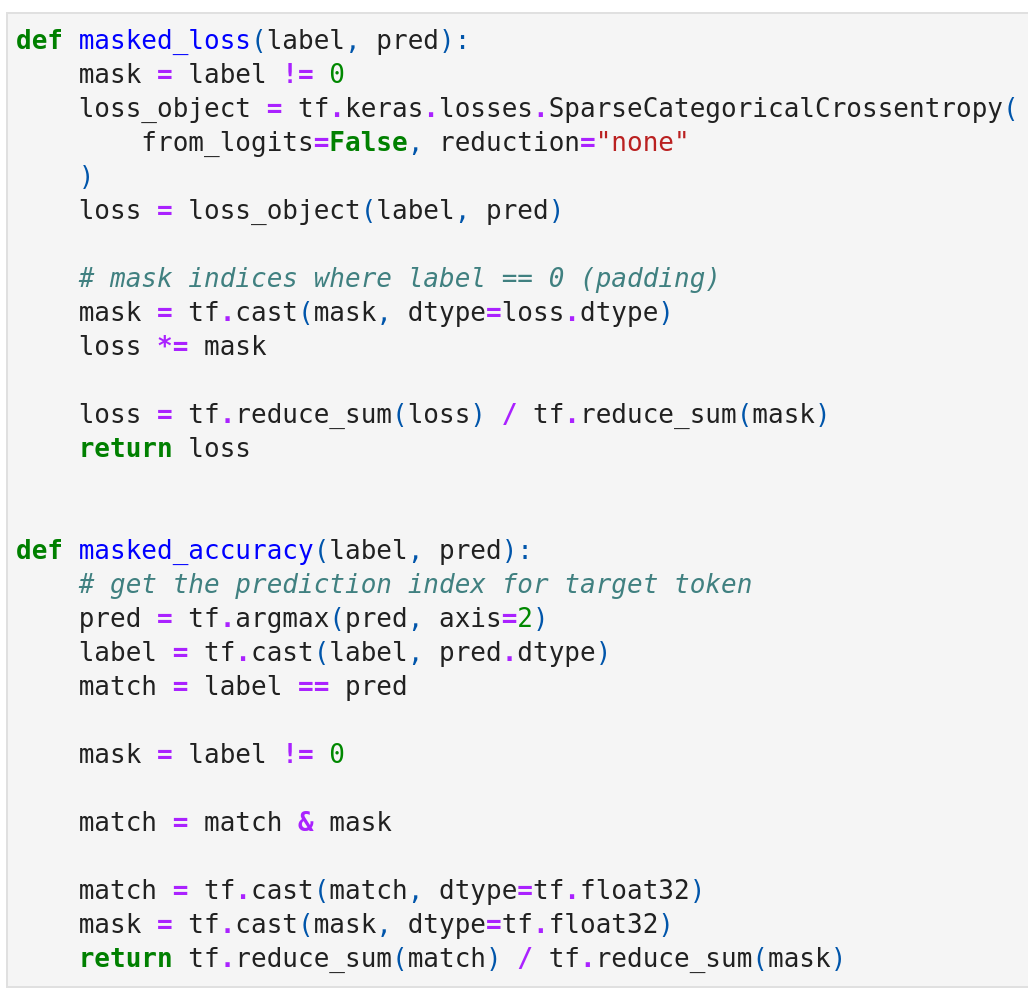
Define the masked_loss and masked_accuracy, here I reuse the code from TensorFlow's official blog. This is actually the same as the loss and accuracy functions in Transformer.
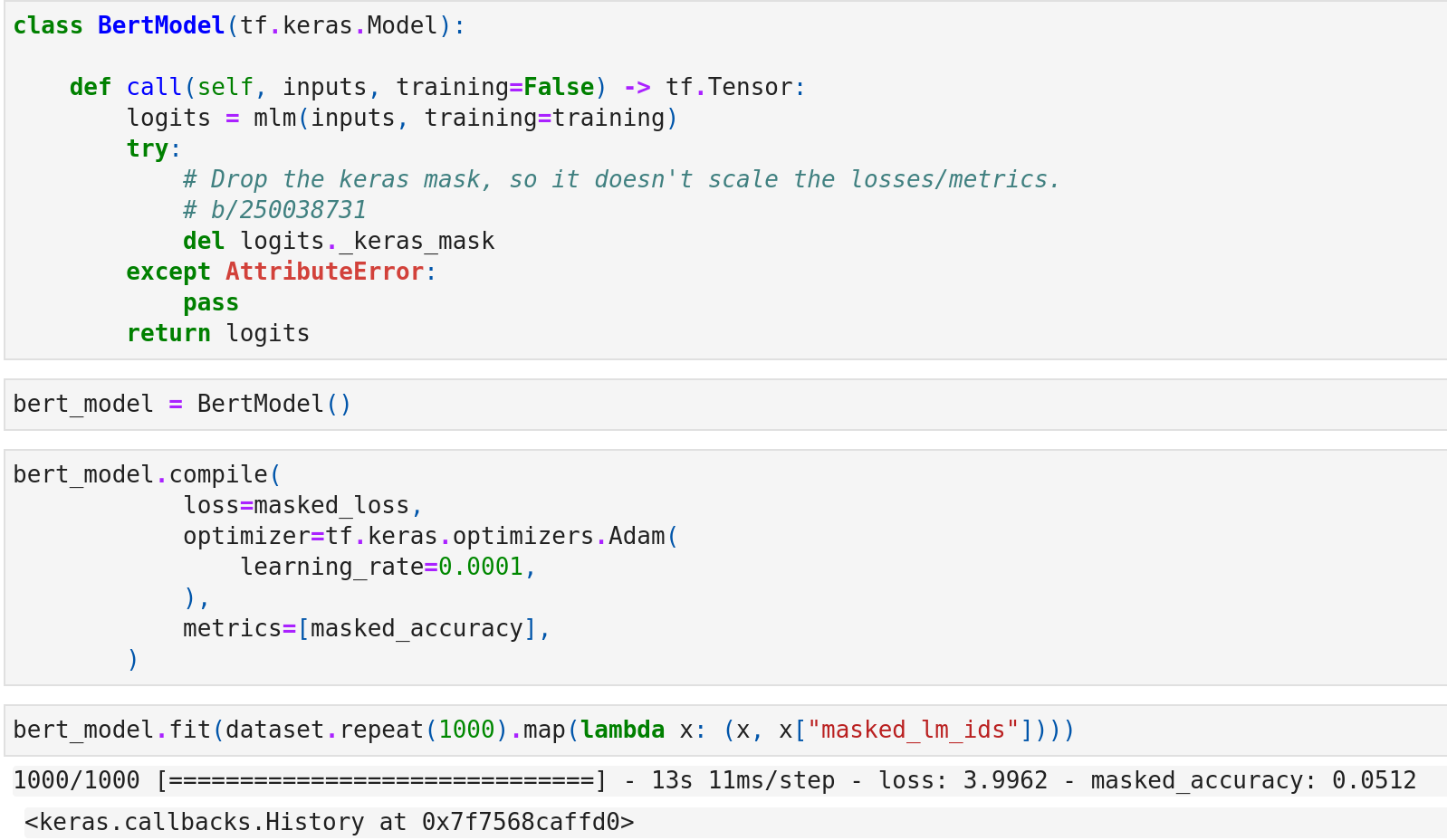
Compile the model and train. Here the masked_lm_ids are the ground truth labels.
Fine-tuning BERT
For each task, they simply plug in the task-specific inputs and outputs into BERT and fine-tune all the parameters end-to-end.
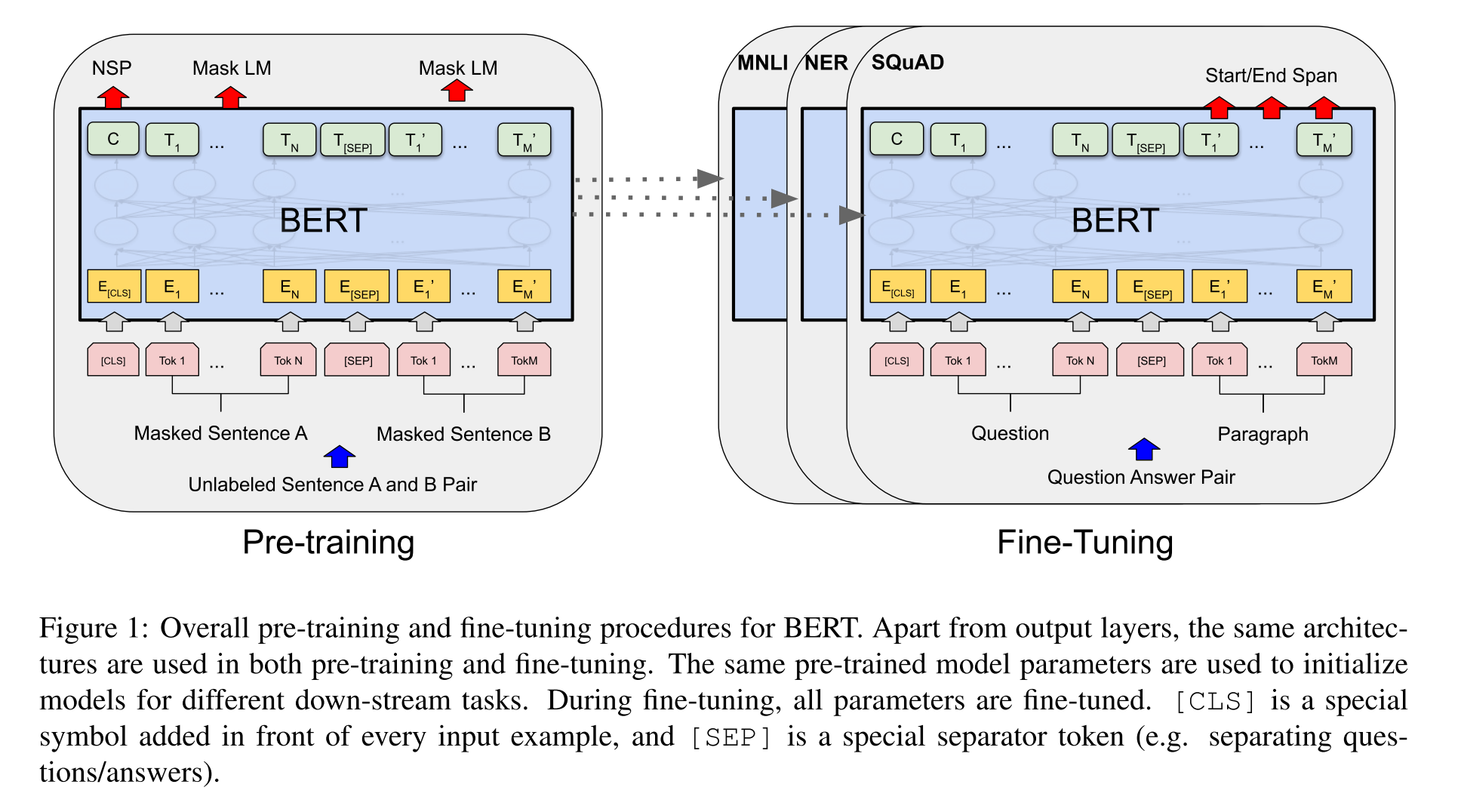
At the input, sentence A and sentence B from pre-training are analogous to (1) sentence pairs in paraphrasing, (2) hypothesis-premise pairs in entailment, (3) question-passage pairs in question answering, and (4) a degenerate text-∅ pair in text classification or sequence tagging.
At the output, the token representations are fed into an output layer for token-level tasks, such as sequence tagging or question answering, and the [CLS] representation is fed into an output layer for classification, such as entailment or sentiment analysis.
Here is an illustration of fine-tuning BERT.
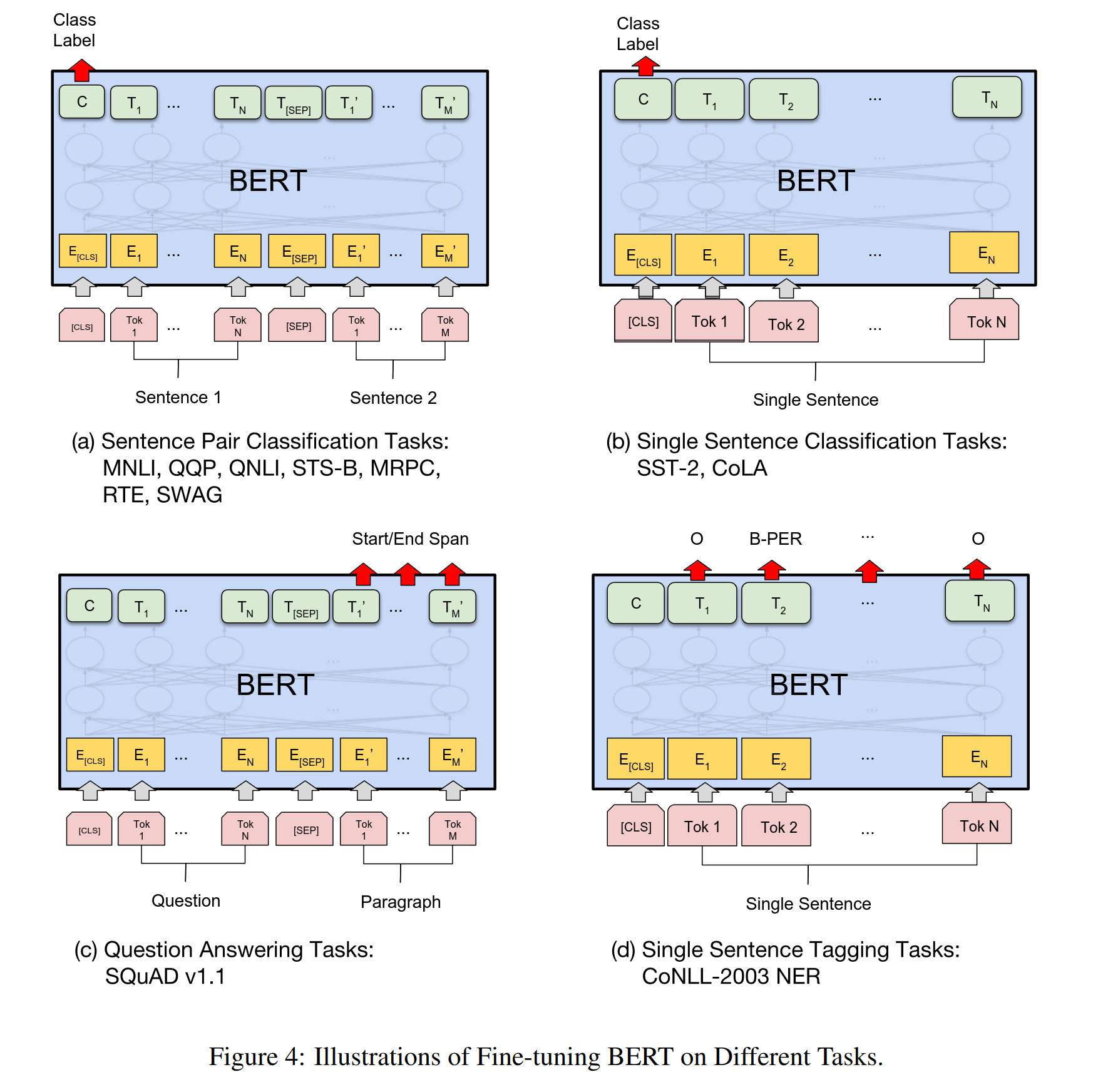
One task worth mentioning is the question and answer task on the SQuAD v1.1 dataset. Given a question and a passage from Wikipedia containing the answer, the task is to predict the answer text span in the passage.
How to model the text span?
They introduce a start vector S and an end vector E during fine-tuning. The probability of word i being the start of the answer span is computed as a dot product between Ti and S followed by a softmax over all of the words in the paragraph. The same logic applies to the end vector E. The training objective is the sum of the log-likelihoods of the correct start and end positions.
The score of a candidate spans from position i to position j is defined as S·Ti + E·Tj , and the maximum scoring span where j ≥ i is used as a prediction.
Experiments
Here are some highlights of the experiments.
BERTBase contains 110M parameters and BERTLarge contains 340M parameters.
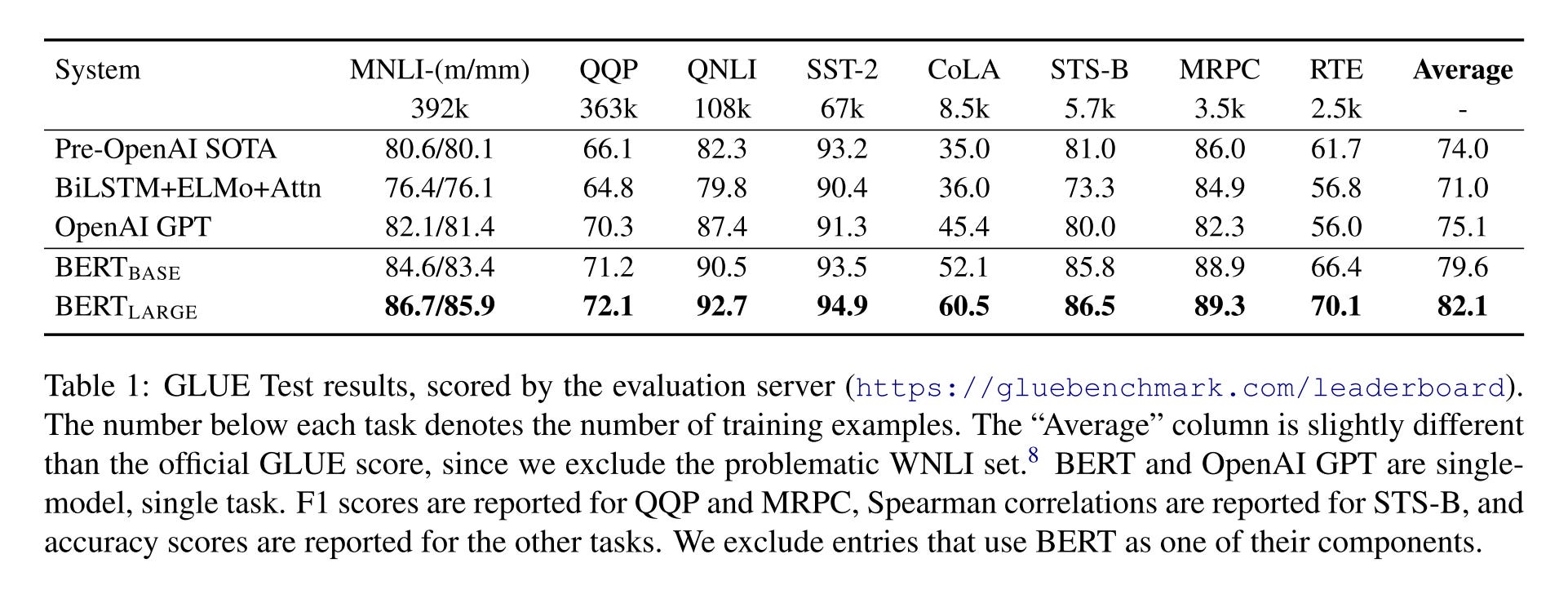
The result of GLUE tests:
Both BERTBase and BERTLarge outperform all systems on all tasks by a substantial margin
BERTLarge significantly outperforms BERTBASE across all tasks, especially those with very little training data
This is the first work to demonstrate convincingly that scaling to extreme model sizes also leads to large improvements on very small-scale tasks, provided that the model has been sufficiently pre-trained
Ablation studies:
Removing NSP hurts performance significantly on QNLI, MNLI, and SQuAD 1.1
The LTR model performs worse than the MLM model on all tasks, with large drops on MRPC and SQuAD
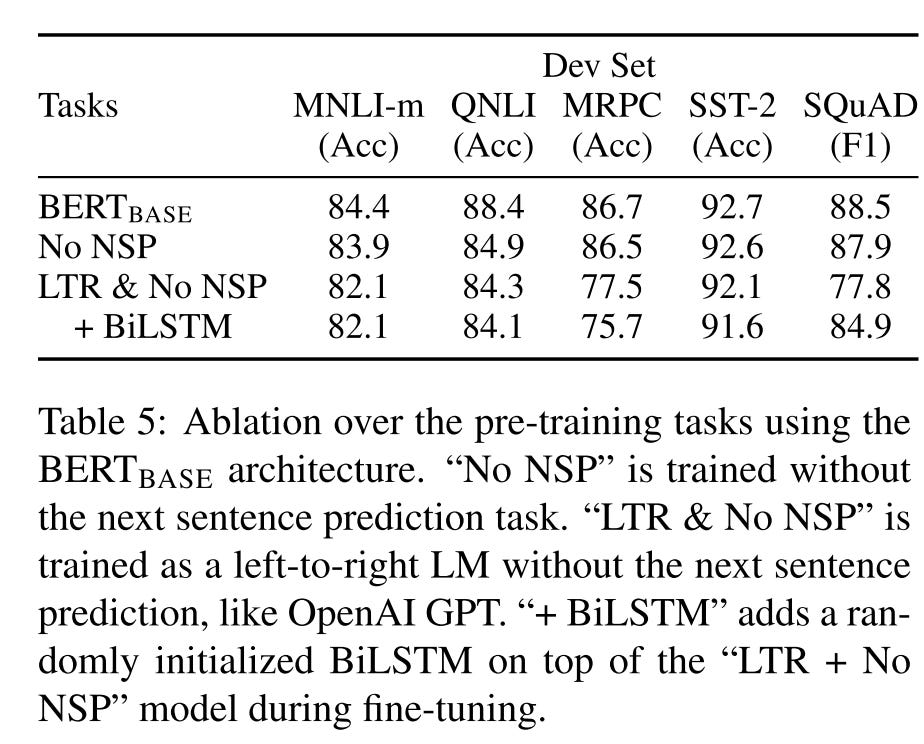
Fine-tuning vs. feature-based:
BERTLarge performs competitively with state-of-the-art methods
BERT is effective for both fine-tuning and feature-based approaches.
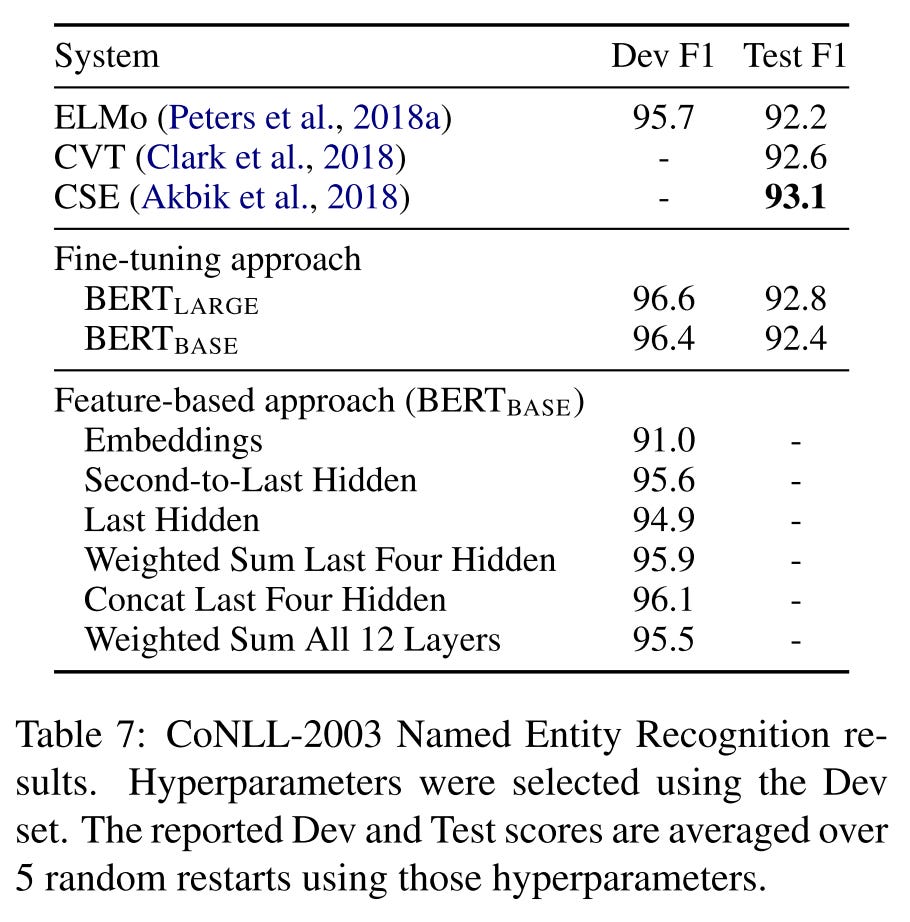
That’s all for BERT.
Enjoy the long weekend, I will also take a break the next week. See you the week after next week 😄.
https://arxiv.org/pdf/1810.04805.pdf
https://blog.research.google/2021/12/a-fast-wordpiece-tokenization-system.html