
Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations - Part I
A major breakthrough in integrating generative LLMs with recommendation systems.

Since the emergence of large language models (LLMs), I have been closely following advancements in generative models within the recommendation domain. LLMs and generative AI have profoundly reshaped not only natural language processing (NLP) but also the broader AI landscape. As a result, many recommendation system practitioners are exploring ways to integrate LLM-inspired modeling techniques into recommendation models. Some key milestones include SASRec and Bert4Rec, which directly adopt Transformer and BERT architectures along with their training methodologies. However, these models primarily come from academic research and are often impractical for real-world industry applications.


There are several critical aspects that are often overlooked in these papers:
Non-stationary Streaming Recommendation Data
Most papers train models on small, static datasets with multiple epochs, which is impractical for large-scale recommendation systems in industry. Real-world recommendation logs are continuously evolving, making it essential to consider streaming data and adaptive training strategies.Recommendation System Architecture
These papers present general recommendation models without addressing the structural differences between candidate generation (CG) and ranking (ranker).Candidate Generation (CG): CG deals with a massive number of candidates, often ranging from millions to billions. To make inference efficient, it is crucial to separate user modeling from item modeling. This separation allows us to amortize inference costs and leverage popular two-tower architectures with approximate nearest neighbor (ANN) search engines to retrieve thousands of candidates efficiently.
Ranker: In contrast, the ranker processes a much smaller candidate set (hundreds to thousands), making it feasible to use more complex model architectures. Research has shown that target-aware modeling is crucial for improving ranker performance. In this setting, interactions between the target item and historical features should occur as early as possible. However, models like Bert4Rec and SASRec do not incorporate the target item into the user sequence, limiting their effectiveness in ranking tasks.
Feature Engineering
Academic papers often overlook feature engineering because it is highly customized to business needs and filled with domain-specific engineering tricks that may not hold much research value. However, in practice, feature engineering remains a key factor in improving model performance. Sequential recommenders, for example, are often criticized for relying only on sparse token features while ignoring dense features such as click-through rate (CTR), count-based statistics, and aggregated user behavior signals.Online Inference
In real-world recommendation systems, server-side latency requirements are typically within a few hundred milliseconds. Despite the increasing complexity of recommendation models, these papers do not discuss strategies for serving and deploying them efficiently in production environments.Experimental Baseline Setting
Many papers compare their models against standard academic baselines with limited feature usage, rather than production-grade models. This makes their results less convincing for industry practitioners, as real-world recommendation systems often employ highly optimized, feature-rich models that significantly outperform these academic benchmarks.
Meta’s recent work on generative recommendation models1 stands out as one of the most significant contributions to the field since the advent of Transformers. This paper introduces several groundbreaking advancements in recommendation modeling:
Reformulating Recommendation as a Generative Task
The paper frames recommendation tasks as sequential transduction problems within a generative modeling framework. In this context, transduction refers to tasks like next-token generation (similar to GPT) rather than traditional induction tasks such as click-through rate (CTR) prediction. This paradigm shift enables a more flexible and powerful approach to recommendation modeling.Unifying Candidate Generation (CG) and Ranking Models
Meta’s approach introduces a novel feature engineering strategy that incorporates only sparse features while skipping dense ones. This method outperforms traditional feature engineering techniques, proving its effectiveness in large-scale recommendation settings. Additionally, they propose a new architecture called Hierarchical Sequential Transduction Units (HSTU), specifically designed for high-cardinality, non-stationary streaming recommendation data. Notably, HSTU is 10x faster than Transformer models based on FlashAttention2, making it highly efficient for real-world applications.Convincing Experimental Results
Unlike many academic papers that benchmark against outdated baselines, Meta’s study compares their generative model directly against their production-grade DLRM models—a highly optimized recommendation system developed by hundreds of Meta engineers over several years. The fact that this model has been successfully deployed in real-world products further validates its effectiveness.Detailed Discussion on Training and Inference Optimization
Large-scale generative models require substantial infrastructure support. This paper provides an in-depth discussion on optimizing training and inference costs, offering valuable insights into how to efficiently deploy such models in production environments while maintaining low latency and high throughput.Discovery of Scaling Laws
The study empirically demonstrates that the performance of generative recommenders follows a power-law scaling with respect to training compute across three orders of magnitude. In simple terms, larger models consistently yield better performance and stronger recommendation impact, reinforcing the trend observed in language models.
New Recommendation Paradigm
Unifying heterogeneous feature spaces
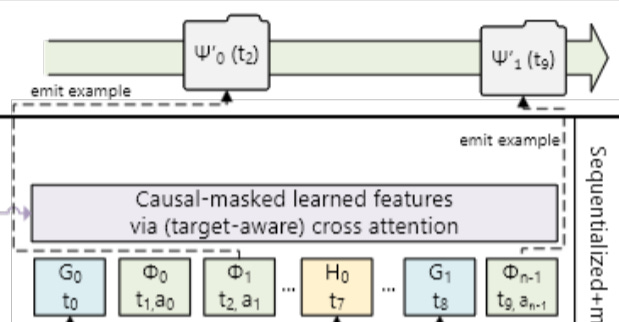
Modern DLRM are usually trained with a vast amount of sparse and dense features. In the new Generative Recommendation (GR), all the features are consolidated into a single unified time series.
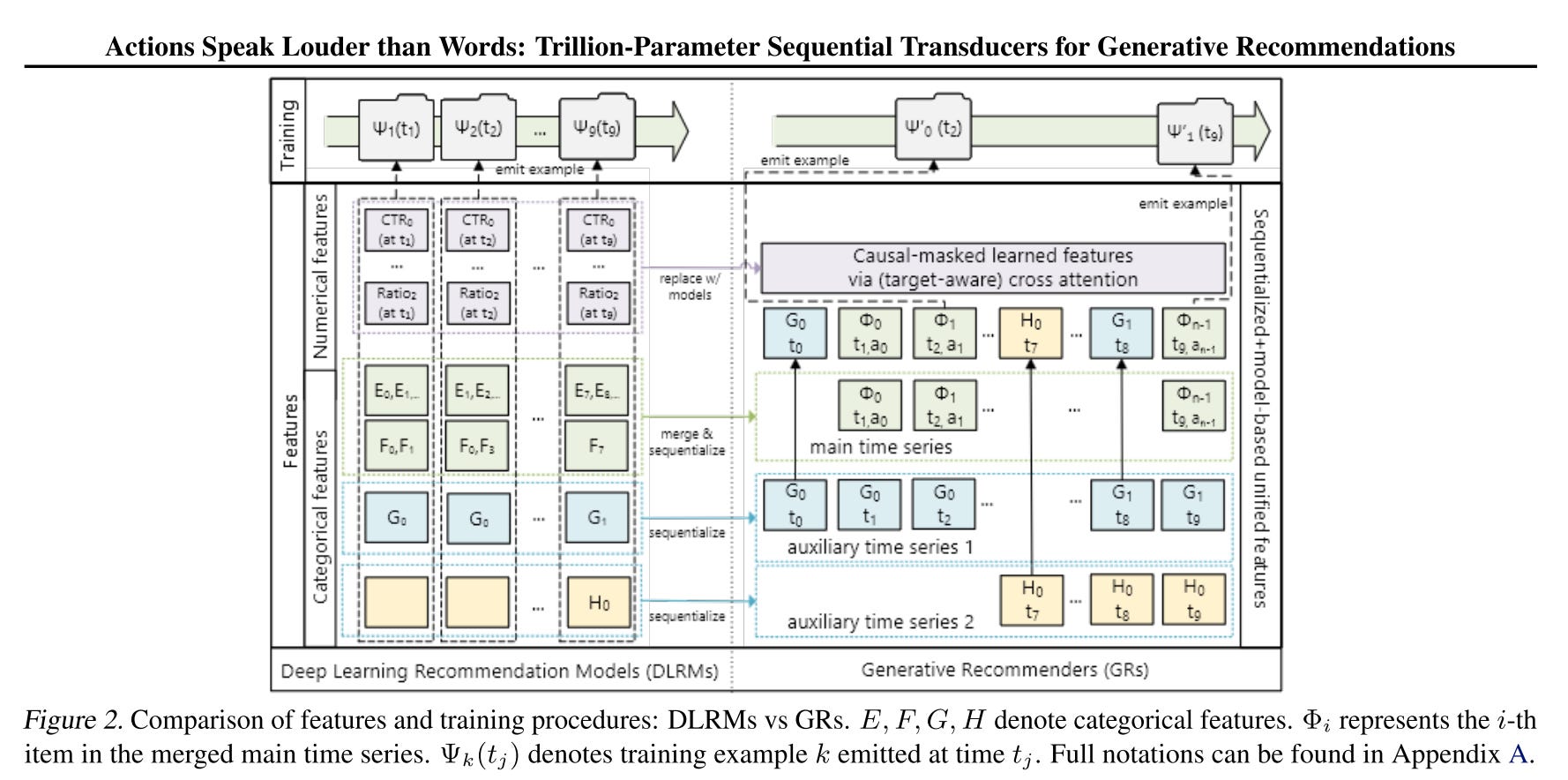
Sparse Features
Sparse features typically include user interactions (e.g., clicks, likes, follows) and user attributes (e.g., demographics). In the generative modeling framework, these features are sequentialized into a unified time-series representation.
Selecting the Primary Sequence
The longest time series is chosen as the main sequence—typically, the user’s clicked item history serves as the backbone of the sequence.Compressing Slowly Changing Features
Some feature series, such as demographics, change gradually over time. To reduce redundancy and improve efficiency, these features are compressed by keeping only the earliest occurrence per consecutive segment and merging it into the main sequence.Example (Figure 2): Suppose the demographic feature G remains at value G0 across timestamps t0, t2, and t3. Instead of repeating G0 at every timestamp, only the first occurrence (G0 at t0) is retained and inserted into the main sequence.
This approach effectively reduces sequence length while preserving essential temporal information, making the model more efficient in handling long-term dependencies.
Dense Features
Dense features are typically numerical statistics derived from user behavior, such as click-through rate (CTR), counters, and ratios. Unlike sparse features, these values change frequently, often updating with every user-item interaction.
In GR, the dense features are completely removed:
Infeasibility of Encoding in Sequential Models
Due to their high-frequency updates, encoding dense features directly into a sequential model (such as Generative Recommenders, GR) is impractical. Traditional sequential encoders like Transformers would struggle with the constantly shifting nature of these features.Implicit Encoding Through Full User History
A key observation is that dense feature information is already embedded within the model's sequential structure. Since GR processes the full history of user interactions in a target-aware setting, the attention mechanism naturally learns the relationships between the target item and past user behaviors.
Reformulating Ranking and Retrieval as Sequential Transduction Tasks
Let x_i represent the input tokens ordered chronologically and observed at time t_i. y_i is the corresponding output token from sequential encoder at t_i, where:
y_i = ∅ means the output is undefined at that timestep.
Φ_i is the a content that system provide to the user. a_i the user’s response on the the item.
Using these definitions, the ranking and retrieval tasks can be formulated as follows:

Retrieval as Next Content Token Prediction
The process of the recommendation system suggesting a content Φ_i (e.g., some photo or video) to the user. The input are constructed as a list of <content_i, action_i> and the corresponding output for content_i is ∅, for action_i is Φ_i+1.
Ranking as Next Action Token Prediction
The process of the user reacting to the suggested content Φ_i via some action a_i (which can be a combination of like, video completion, skip, etc.). The input are constructed the same as the retrieval tasks and the corresponding output for content_i is action_i+1, for action_i is ∅.
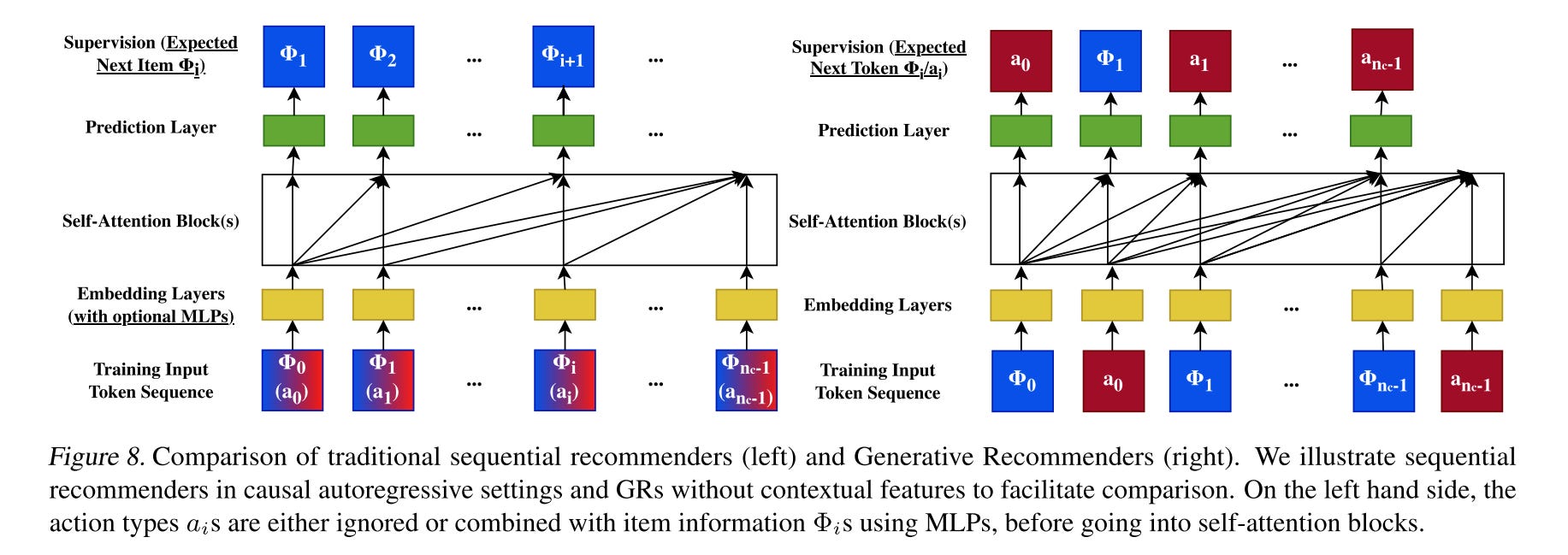
This reformulation differs from traditional sequential recommenders in several key ways:
User Actions as Input Tokens
Instead of treating only consumed items as input, both positive and negative user actions are explicitly modeled as input tokens.
Incorporating Negative Actions
Negative actions (e.g., skips, dislikes) are also included in the input sequence, providing richer behavioral context.
Retrieval Task Reformulation
For the retrieval task, the output token y_i is undefined (y_i=∅) under the following conditions:
When the input token represents a user action a_i and the response is negative.
When the input token represents content x_i.
This can be effectively implemented using masking mechanisms.
Ranking Task Reformulation
For ranking, the target item is inserted as the last input token to the encoder.
The output y_i is then the predicted user action on this target item, making the approach inherently target-aware.
Amortize Computation Complexity
The total computational requirement for the original Transformer is:
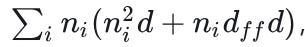
The first part comes from the self attention calculation
The second part comes from the pointwise MLP layers
Notice here there is an extra
n_ion the left, this is because how we construct the training samples - in a naive setting, for each new token, we will take it as a new training sample and feed it to Transformer for training. So the total complexity will be the sum of all tokens
As show on the top of Figure2, we can reduce the training complexity by n through a simple sampling strategy - only emit training examples at the end of a user’s request or session. The sampling rate is proportional to 1/n.
High Performance Self-Attention Encoder
The Hierarchical Sequential Transduction Unit (HSTU) is the key model innovation introduced in this paper. As shown in the diagram below, it consists of multiple identical self-attention blocks, but with notable differences from standard self-attention modules.
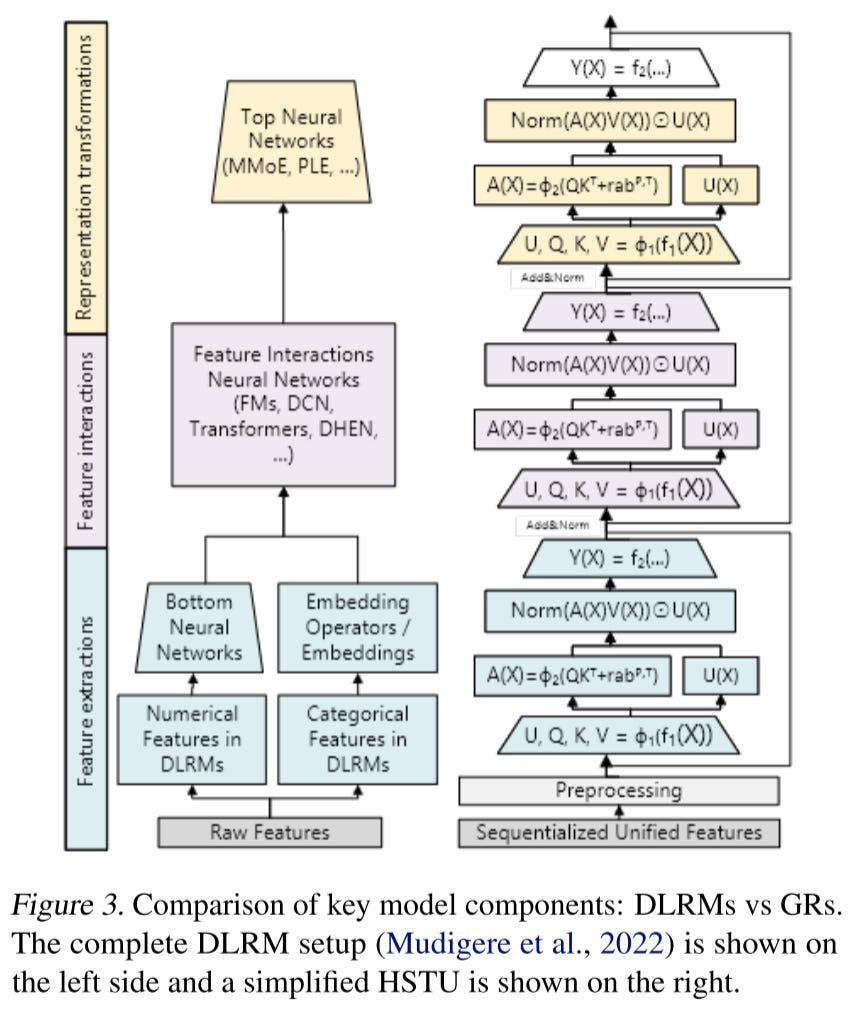
Each block contains three sub-layers:
Pointwise Projection (Equation 1)
Spatial Aggregation (Equation 2)
Point- wise Transformation (Equation 3)
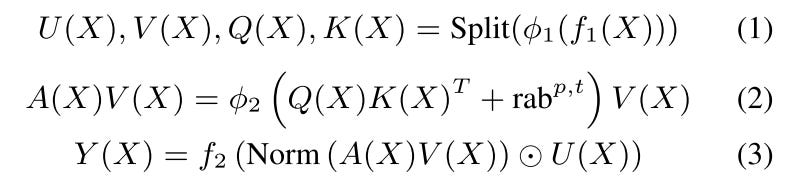
Note here f_1(x) is a one simple linear layer. ϕ denote nonlinear transform activation which is SiLU. U(X) is a new projected weights used for gating. Recall the similar ideas from MaskNet and DCN, the U(X) is for keep the original feature and create the high order interaction. rab(p,t) denotes relative attention bias that incorporates positional (p) and temporal (t) information (the author doesn’t share details about how to realize this rab, they just mentioned that one possible implementation is to apply some bucketization function to (tj − ti) for (i, j)). Norm operation is LayerNorm.
Compare to DLRM
The Deep Learning Recommendation Model (DLRM) typically consists of three main components:
Feature extraction
In DLRM, this involves pooled embeddings of sparse features or target-aware pooling.
In HSTU, this process is naturally handled by self-attention, which enables dynamic feature aggregation across tokens.
Feature interaction
Feature interaction is one of the most critical parts of DLRM.
In HSTU, interactions are extracted through the feature gating mechanism, represented as: Norm(A(X)V(X))⊙U(X)
Here, attention-pooled features directly interact with U(X), allowing for adaptive and context-aware feature interactions.
Representation transformation
DLRM typically uses Mixture of Experts (MoE) and routing to enable conditional computation, where different subnetworks specialize in handling different user behaviors.
In HSTU, this is implicitly achieved through the element-wise dot product with U(X), making computation more efficient and scalable.
Compare to Transformer
HSTU adapts and customizes the original Transformer structure to better suit recommendation requirements.
Pointwise Aggregated Attention Mechanism
One of the key changes in HSTU is the removal of the softmax operation from the attention mechanism. This decision is motivated by two primary factors:
User preference intensity is crucial for recommendation tasks, and softmax normalization can dilute this intensity. For instance, if a user has listened to many hip-hop songs in the past, the model should leverage the density of hip-hop preferences to more accurately predict their time spent on a new hip-hop track. Softmax normalization would diminish this intensity, causing the model to lose crucial information about the user's history.
Softmax is less suitable for non-stationary vocabularies in streaming settings. Based on empirical tests, it has been found that softmax struggles to handle dynamically changing user interactions over time, making it less effective in real-time recommendation scenarios.
Additional Projection Weights and Element-wise Gating Mechanism
HSTU introduces an extra projection weight U(X) and the element-wise gating mechanism to manage feature interactions more effectively. This mechanism allows for more flexible and context-sensitive feature aggregation.
The below result on synthetic data show the performance gaps as large as 44.7% between HSTU and Transformer.

Performance Optimization
Another important challenge is how to train and deploy such a large model to a production environment. At Meta, this responsibility is handled by their Infra team, and they have applied several different, effective approaches together to address this issue.
Increase Sparsity
In recommendation, user history usually follows skewed distribution, most histories are short while some are extremely long. This can be further leveraged to improve the efficiency of encoder.
Develop a new GPU kernel works like FlashAttention
It divide attention attention into grouped GEMMs (General Matrix Multiplications) of various sizes. And the self-attention becomes memory bounded and scales register memory size increase. This leads to 2-5x throughput gains.
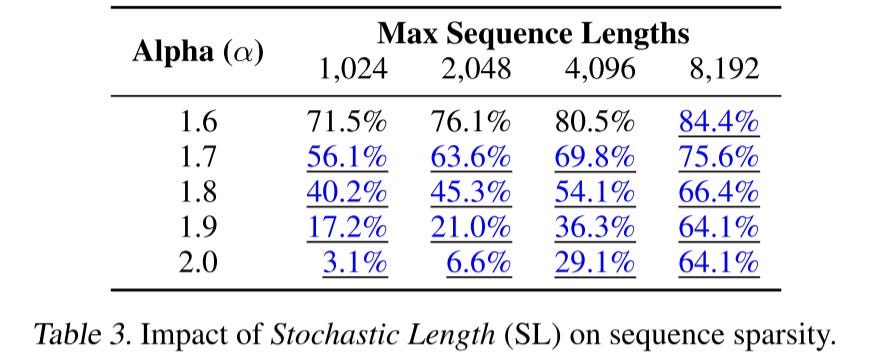
Stochastic Length (SL)
the user behaviors in recommendation history is temporarily repetitive. So we can artificially increase sparsity by down sampling user histories. Here
x_iis the user history item,n_c,jis the number of contents user interacted with.Nis the max number of interacted contents.αis a tuning hyper parameter to control the sampling rate. SL select sub-sequence as follows: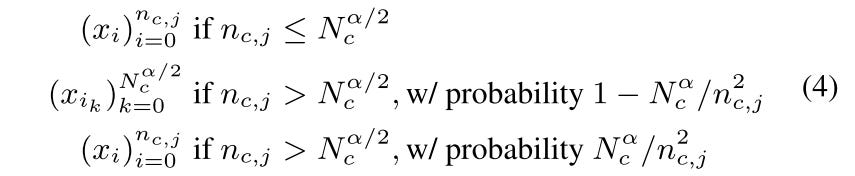
If the current sequence length <
N^α/2.Then keep it.If current length >
N^α/2,sampling the history to lengthN^α/2with a probability of 1 -N^α/n^2Otherwise, keep the original sequence with probability of
N^α/n^2Here is the result on a 30-day user history, when
α=2means there is no SL applied, but we can still see the inherent sparsity increase as the sequence length grows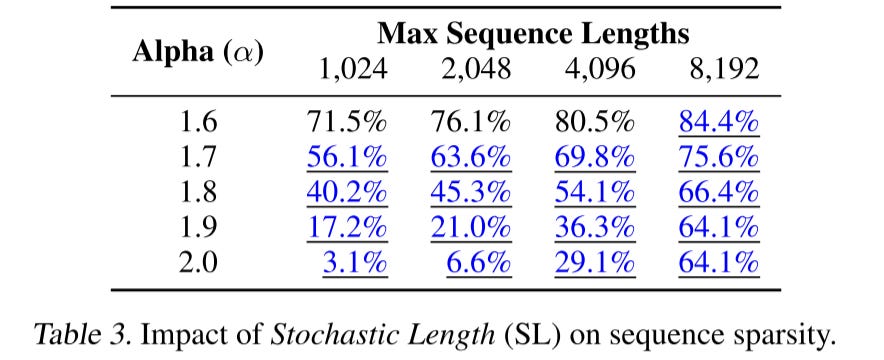
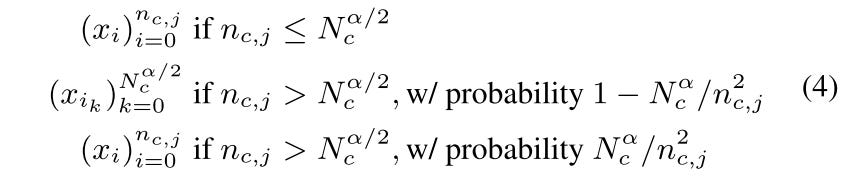
Minimize Memory Consumption
In recommendation system, the use of large batch sizes is crucial for both training throughput and model quality. So activation memory usage is the major bottleneck.
In HSTU, it employs several approaches to reduce memory usage:
Reduce the number of linear layers out of attention from 6 to 2
Fuses computations into single operators, including
ϕ1(f1(·))in Equation (1), and layer norm, optional dropout, and output MLP in Equation (3).Large scale atomic ids used to represent vocabularies also require significant memory usage. Instead of original Adam, they use rowwise AdamW optimizer to place optimizer states on DRAM instead of HBM, which reduces HBM usage per float from 12 bytes to 2bytes.
Scaling Up Inference
The last part focuses on optimizing inference speed when serving a large number of candidates online. It primarily discusses the ranker rather than the retrieval system, as retrieval inference is already addressed by existing methods like ANN search.
For ranking, they propose M-FALCON (Microbatched-Fast Attention Leveraging Cacheable OperatioNs) to efficiently perform inference for m candidates with an input sequence size of n. M-FALCON handles b_m candidates in parallel by modifying attention masks and biases (denoted as rab_p,t) to ensure that the attention operations for b_m candidates are identical.
One-Pass Inference
Conventional wisdom suggests that in a target-aware setting, inference needs to be performed for one item at a time, with a computational cost of O(mn^2d) for m candidates and sequence length n.
By modifying the attention mask, the inference process can be done in one single batch, reducing the cost to O((n+m)^2d)=O(n^2d)
This is achieved by allowing the candidate to attend only to the user’s history and preventing candidates from attending to each other using masking tricks.
Microbatching Large Candidate Sets
When dealing with tens of thousands of candidates, the candidates are divided into ⌈m/b_m⌉ microbatches of size b_m, where O(b_m) = O(n)
This retains the time complexity of O((n + m)^2d), but with the added benefit of efficient parallel processing for large sets of candidates.
There’s a constant coefficient ⌈m/b_m⌉ that is typically ignored for simplicity in analysis.
KV Cache
KV caching allows for the reuse of computation results for K(X) and V(X), improving the efficiency of subsequent inference steps by not recalculating these values for each candidate.
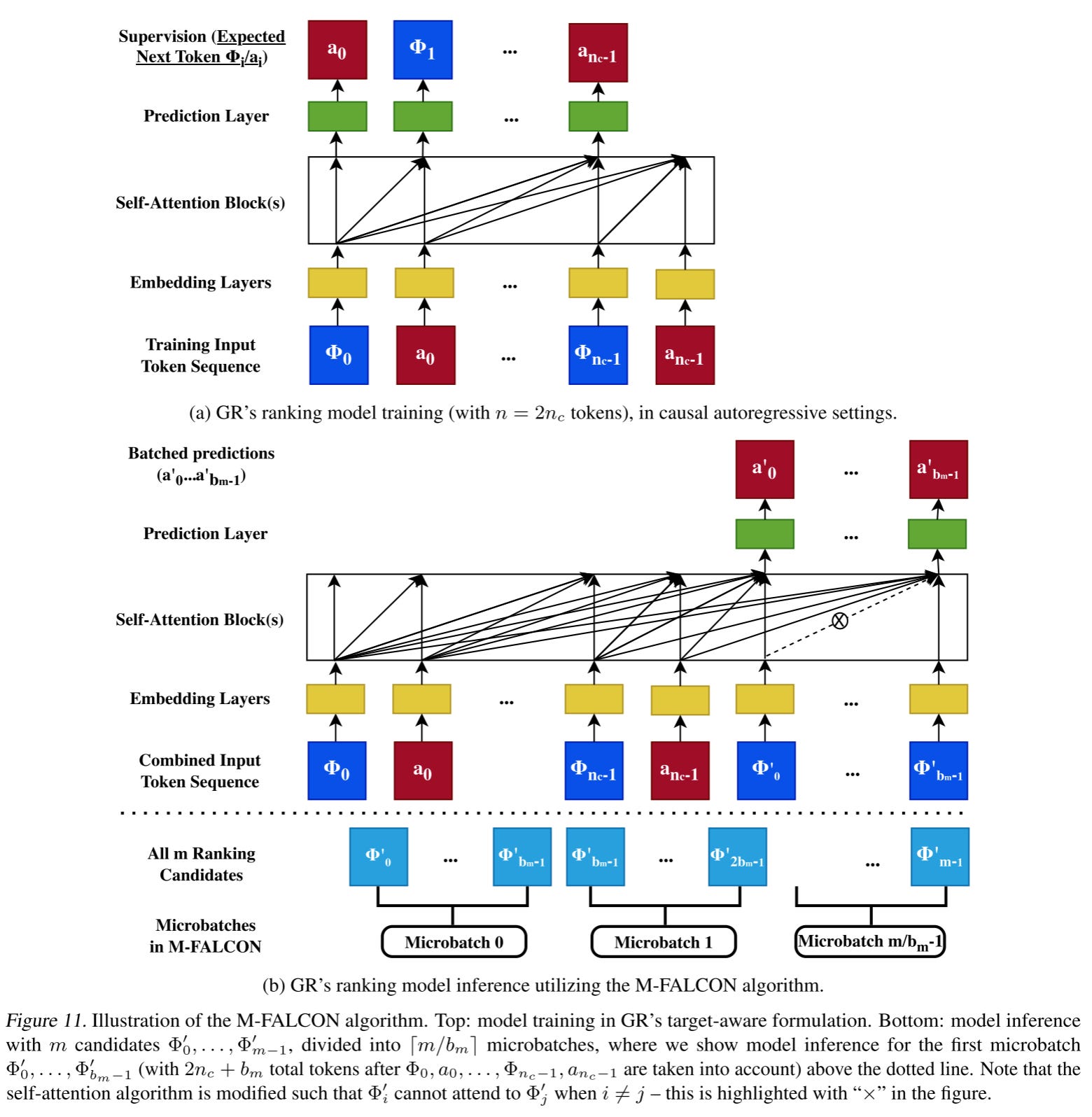
Overall, M-FALCON can achieve 285x more complex target-aware cross attention model at 1.5x-3x throughput with a constant inference budget.
We can see that there are numerous details that require careful reading and understanding, as well as the collective effort of multiple teams to implement. In the next post, we will discuss the experimental results and address some frequently asked questions about this paper.
https://arxiv.org/abs/2402.17152
was trying to read this paper in detail this weekend and found this! nice
I am still puzzled by how exactly it is used for candidate retrieval after reading the paper multiple times. Say, we already have the Generative Recommenders (GR) retrieval model, does the candidate generation is just let the model outputs (predicts) the 1,000 candidates?