

BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
When BERT meets sequential recommendation

As I previously discussed in the SASRec post, BERT4Rec was another model that received considerable recognition at the RecSys conference. Today, let's delve into how the BERT model functions within the realm of sequential recommendation.

BERT4Rec Illustration
In contrast to SASRec, which leverages the Transformer's decoder component, BERT4Rec brings a significant enhancement through the incorporation of Bidirectional Encoder Representations, aligning with the BERT concept.
If you're not well-acquainted with the BERT model, I recommend referring to my earlier post for a comprehensive introduction.

Now, let's examine the architecture of BERT4Rec, starting from the foundational components and working our way to the top:
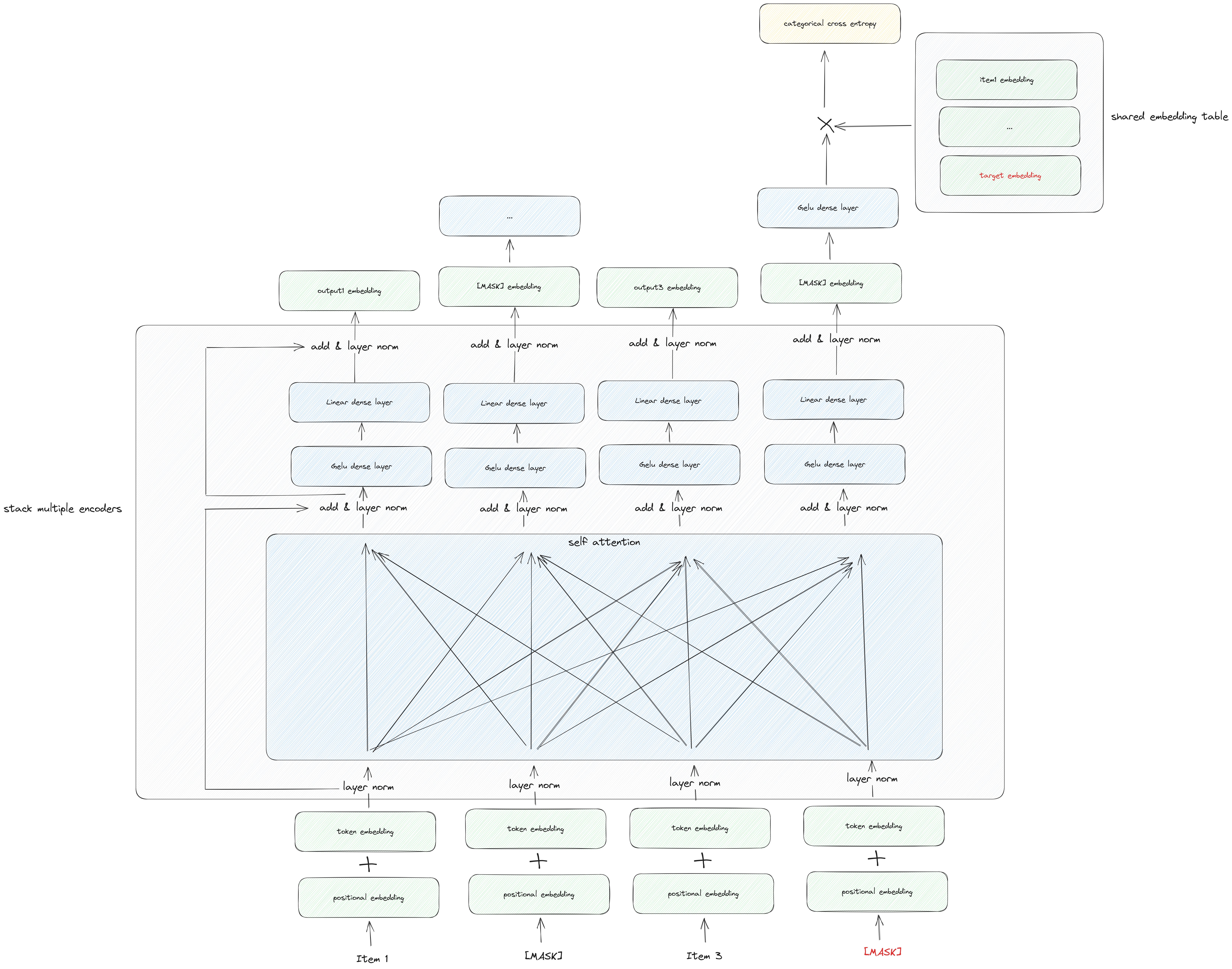
Embedding Layer: The input layer closely resembles BERT's input, with the exception of excluding the segment embedding. This deviation stems from the fact that in user behavior sequences, items naturally relate to one another. In contrast to BERT's task of predicting the next sentence, which necessitates an explicit separator for input like question and answer pairs, no such separation is required here. It's important to note that in the picture, item2 and item4 are masked, following the same training approach from BERT, known as the masked language model. An illustrative example is as follows:
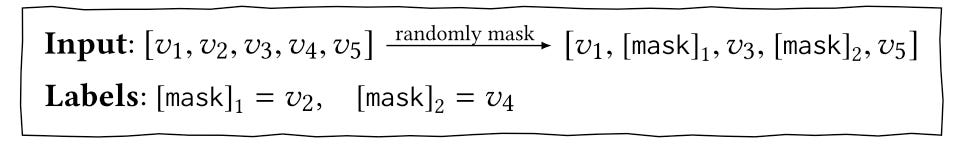
Layer Normalization and Residual Connection: These components align with those in BERT and serve a similar purpose.
Self-Attention and Feed-Forward Layers: The self-attention mechanism diverges from SASRec. In this configuration, there is no causal mask, enabling all items to attend to one another. Additionally, the feed-forward layer introduces a single difference—the activation function is Gelu (Gaussian Error Linear Unit), a choice generally considered to deliver superior performance compared to Relu.
Output Layer: The output layer significantly departs from the SASRec model. An additional Gelu dense layer is incorporated to extract supplementary information. Given that we employ the Masked Language Model (MLM) for training, there is no rightward shift in the target item. The original item serves as the ground truth; for instance, for the masked item4, item4 remains the target item. Furthermore, there is no negative sampling involved. The output embeddings are multiplied by the entire embedding table, and the final result is then subjected to categorical cross-entropy. This categorical cross-entropy comprises a combination of a softmax and binary cross-entropy operator.
It's worth noting that in this setup, the embedding table is shared between the input and output layers, serving the purpose of reducing the model's overall size.
BERT4Rec vs. SASRec
Now that we've identified the major difference between these two models as the introduction of bidirectional encoder representations, a question may arise:
Why isn't BERT4Rec concerned about information leakage, a concern addressed in SASRec?
The reason is that bidirectional encoder representations are solely applied during the training phase of BERT4Rec. During training, the model already has access to all previous user behaviors, so it is acceptable to attend to all behaviors, whether they occur on the left or right side of the current item being predicted.
Additionally, BERT4Rec includes a unique approach by appending a special token, "[mask]", at the end of the input sequence to indicate the item for prediction. Recommendations are then generated based on the final hidden vector of this token.
During training, BERT4Rec also generates samples where only the last item in the input sequences is masked, addressing this issue.
BERT4Rec vs. BERT
Recall that in BERT, we distinguish between two distinct phases: the pre-train and fine-tune stages. However, in BERT4Rec, there is no fine-tuning phase. The most significant departure lies in the fact that BERT4Rec is a comprehensive end-to-end model tailored for sequential recommendation, whereas BERT primarily serves as a pre-training model for sentence representation.
BERT leverages extensive, task-independent text corpora to pre-train its sentence representation model, preparing it for a variety of text sequence tasks. This approach is effective because these tasks share a common foundation of language-related knowledge. However, this assumption doesn't hold true in the context of recommendation tasks.
Another notable distinction lies in the absence of next sentence loss and segment embeddings in BERT4Rec. This deviation arises from the fact that BERT4Rec models a user's historical behaviors as a single sequence within the context of sequential recommendation tasks.
Experiments
In the paper, the authors conducted a series of comprehensive experiments to thoroughly assess and validate the model's performance. Here are the key findings from these experiments:
Overall, BERT4Rec demonstrates a substantial performance improvement over the baseline. On average, it exhibits approximately a 10% increase across all metrics measured.
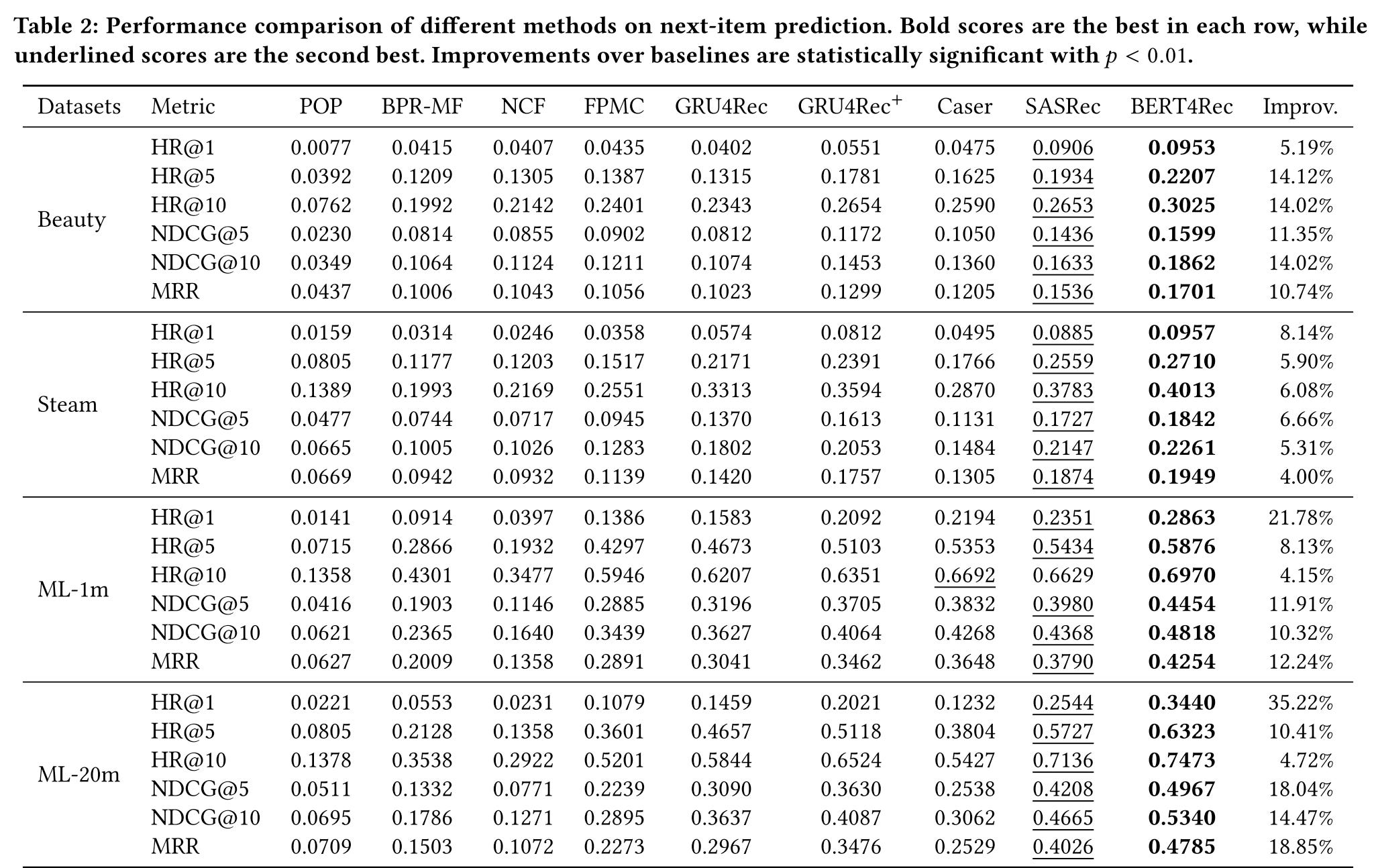
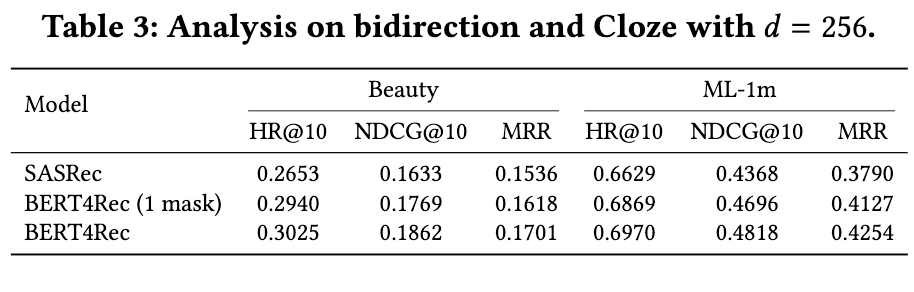
Do the gains come from the bidirectional self-attention model or from the Cloze objective?
The results show that BERT4Rec with 1 mask (only predict the last item) significantly outperforms SASRec on all metrics. It demonstrates the importance of bidirectional representations for sequential recommendation. Besides, the last two rows indicate that the MLM also improves the performances.
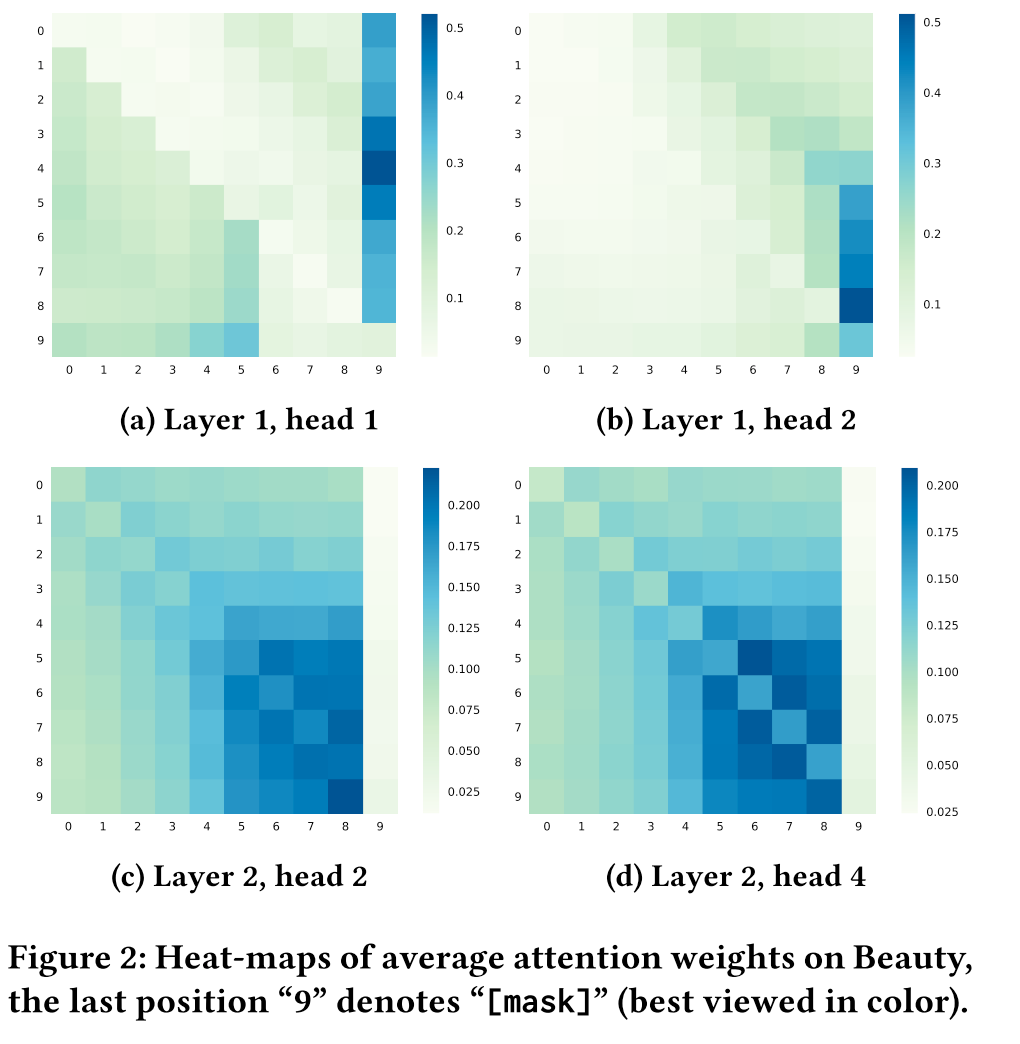
Why and how does bidirectional model outperform unidirectional models?
As we can see from the heatmap, unlike unidirectional model can only attend on items at the left side, items in BERT4Rec tend to attend on the items at both sides. This indicates that bidirectional is essential and beneficial for user behavior sequence modeling.
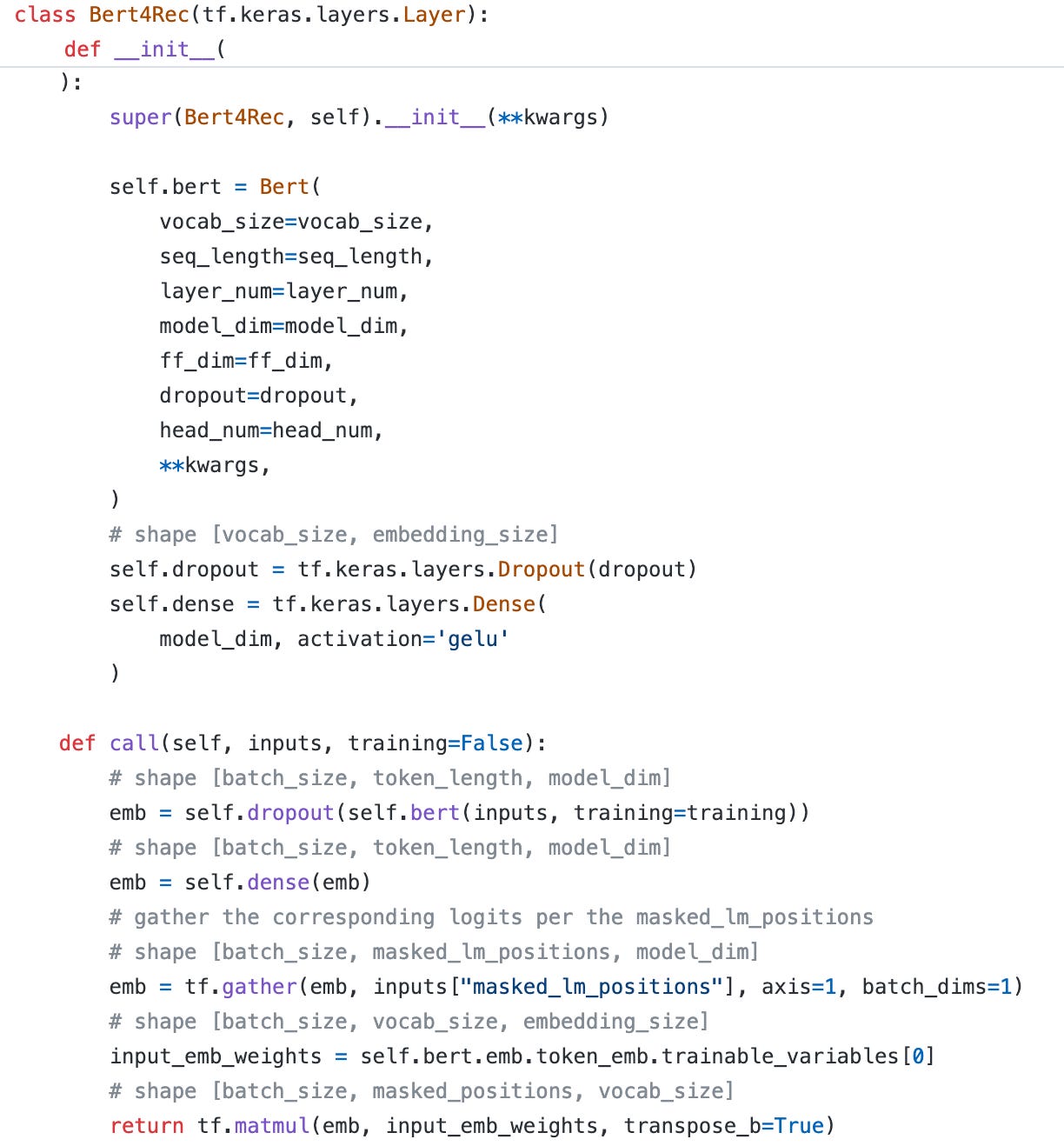
Implementation
You can view the whole example through this link.
The official code is written in TensorFlow 1.0 and Estimator API which is a little bit messy. You can find it here.
While most of the code remains consistent with BERT, I'll emphasize the significant differences below:
An additional Gelu dense layer is tacked onto the output.
Following the collection of masked positions, we obtain the token embedding table for the purpose of weight sharing (Notably, we cannot employ the "get_weight" function here, as it would lead to errors during training).
We utilize a matrix multiplication operation to compute the logits for each position, which is subsequently used in the calculation of categorical cross-entropy loss.
That concludes our discussion on BERT4Rec. I'm confident that with a solid grasp of the Transformer and BERT models, comprehending the BERT4Rec model is a breeze! 😄
I'm curious how this model performs in real production, as it doesn't use any other features at all. IMO, it probably would be a backbone model to extract user sequence embedding, which'd be fed into another ctr model along with all other features.
hdyt?