
Dive into Twitter's recommendation system I - RealGraph
RealGraph: User Interaction Prediction at Twitter

Start from this one, I will write a series of articles to go through the details of Twitter’s recommendation system.
The first article is about Twitter’s in-network candidate retriever - RealGraph1. This paper
is a bit old, first published in 2014, and the core algorithm is the traditional LR
mainly focus on the feature engineering work. This is also the inherent need of using LR
proposes a framework to produce a directed and weighted graph where
the nodes are Twitter users, and the edges are labeled with interactions between a directed pair of usersconducts a detailed feature experiement and explains the feature importance
Twitter’s recommendation system
In Twitter’s official blog, they share the architecture.

Compared to common recommendation system, this one:
has the similar architecture, candidate retriever + ranking + post-ranking
heavily rely on graph algorithms for candidate retriever, like RealGraph and Social Graph
find candidates from people you follow (In-Network) and from people you don’t follow (Out-of-Network). The For You timeline consists of 50% In-Network Tweets and 50% Out-of-Network Tweets on average
And the most important component in ranking In-Network Tweets is Real Graph.
Real Graph
What’s is RealGraph?
The RealGraph is a directed, edge-labeled, weighted graph where the nodes are Twitter users, and the edges are labeled with interactions (from a fixed, extensible set) between a (directed) pair of users. Each edge also has a weight that is interpretable as tie strength and defined as the probability of any interaction going from the edge source to the edge destination in the future.
We can see that Twitter is modeling the interaction between two users into a binary classification problem.
RealGraph has been used:
in user recommendation system Who To Follow, it is a random walk algorithm that runs on the Twitter social graph. The output weights of RealGraph is used to guide the random walk
as an effective pre-processing mechanism for finding the top-k connections of a user. Directly use the weight to measure the user relevance
in other products, like search on Twitter, and the Discover page. The weights are used as the input feature for personalized scoring
for discovering similar users on Twitter2 that has applications in ads targeting, collaborative filtering and community detection
The pipeline
RealGraph consists of three components:
Graph and feature generation, how to build the user connections and features
Feature scoring, how to train a LR model
Application, how to apply to downstream jobs
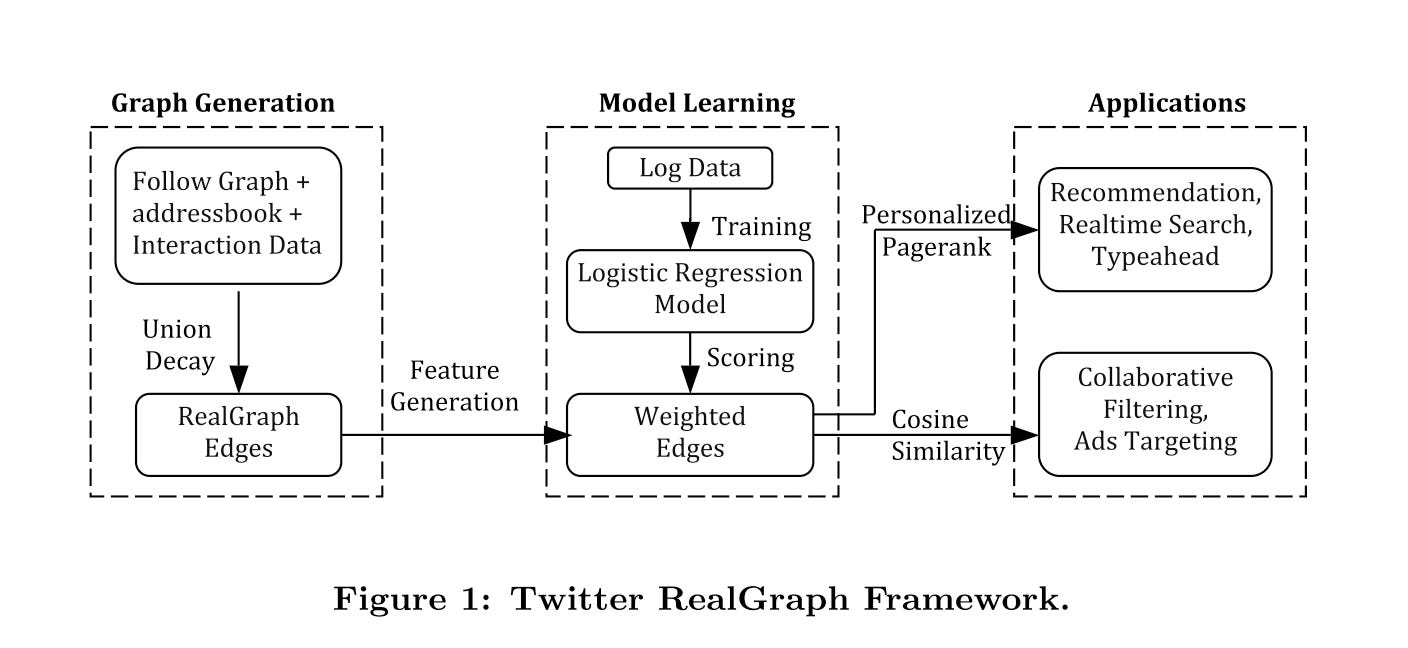
Graph generation
Add a edge for user pairs if:
A follows B
B is in A’s phone or email address book (only if the requisite permissions have been granted by the users)
A interacted with B
The RealGraph is computed on a daily basis in a incremental way to prevent snowballing:
merge new edges with previous day’s RealGraph
decay historical interaction values and remove an edge if the most recent interaction is too old
Edge features
Three variants for follow relationship:
a one-directional follow (the most common)
two-directional follows (where both users follow each other)
SMS-follow where A not only follows B, but has opted in to receive all of B’s tweets as either SMS or in application notifications
They store the number of days since the edge created as the feature.
Two kinds of interactions:
Visible interactions (from B’s viewpoint)
A retweets B’s tweet
A favorites B’s tweet
A mentions B (via their handle), or Amessages B
Implicit interactions
A clicks on B’s tweet or on a link within the tweet
A visits B’s profile page.
Then create several dense features for interactions:
Non-zero days: the number of days when such an interaction happens
Mean and variance: the mean and variance of interaction counts (computed over non-zero interaction days)
Decayed count: a daily exponentially-decayed interaction count (EWMA)
Days since last interaction: number of days since the last interaction of this type
Elapsed days: number of days since the first interaction of this type happened
And some extra features:
the number of different non-zero interaction types for an edge as we have found diversity of historical interactions between two users to be a good indicator
the number of common friends (users that both follow and are followed by A and B) to measure closeness in terms of the graph
topic-related edge features on each edge, the number of common topics between source user’s interested-in and destination user’s known-for based on a 300 topic taxonomy
User features
Aggregation the edge features as the source user’s sending-feature and the destination users’s received-feature
Other features represents user activity and reputation:
These include number of tweets in the last week
language
country
number of followers
number of people they follow
PageRank on the follow graph
🤔 My comment: there is a good example of how to design features for graph relationships. Feature engineering is all RealGraph need
Model training and scoring
The target is defined as to predict interactions in a period given feature values before beginning of that period (and taken from a period of the same length).
They also add heuristic rules to filter out noisy edges, a edge is valid:
only if the destination user wrote at least one tweet in the test period, and if the source user had created at least one interaction in the test period
🤔 My comment: guess this is just for reduce the training data size
Regarding the label:
The training label for an edge is set to 1 or -1 depending on the existence of any interaction. 🤔 My comment: why not 0 or 1, Twitter doesn’t share any detail, guess they just scale the result of sigmoid
Thus, the training task is to learn what combination of features in a period can predict whether there will be any interaction on the same edge in the future. 🤔 My comment: here every interaction is treated the same, this is not a good approach, some interactions like retweet should be more important than click
Evaluation
Two ways of evaluation:
Feature importance test, calculate AUC for different feature groups
User survey, nothing special here
How to extract the graph data:
One week of interaction data
Build a RealGraph for the first day of week using the remaining day’s data
To emphasize the implicit interaction, they give it 5x weight of implicit interactions while sub-sampling
If there is any interaction in the following days, the label will 1 and vice versa
They don’t balance the positive and negative instance
🤔 My comment: yeah, negative sample ratio doesn’t affect the result much. They don’t mention how to build validation dataset, I guess they are using the data from next week
Here are the AUC results for each feature group.

We can see that:
non_zero_days has a big gain of 0.019
user reputation has another moderate gain of 0.003
user activity has another big gain of 0.022, including number of posted tweets, number of sent favorites and user’s country
Conclusion
That’s it, there is nothing magic but hard feature engineering work with LR model. But this is still a very good example for feature engineering.
Weekly digest
大语言模型的涌现能力:现象与解释, how to explain the emergent ability of LLM? The author summarize the popular ideas and shares his own thought
Cheating is All You Need. This is an advertorial but still bring interesting ideas on the influence of LLMs for programmers.
software engineering exists as a discipline because you cannot EVER under any circumstances TRUST CODE. Bug is the nature of coding, so is LLM’s code
all the winners in the AI space will have data moats. This is the essential part of construct context for LLMs
THE AI INDEX REPORT from stanford
The Recommendation System at Lyft, hmm Lyft is still using LightGBM
What’s next
Let’s continue the journey of Twitter’s recommendation system, next article will be about the out-network candidate retriever - Social Graph (GraphJet: Real-Time Content Recommendations at Twitter)3
https://www.ueo-workshop.com/wp-content/uploads/2014/04/sig-alternate.pdf
http://snap.stanford.edu/mlg2013/submissions/mlg2013_submission_20.pdf
https://www.vldb.org/pvldb/vol9/p1281-sharma.pdf