
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
The Classic sequential multi-task model from Alibaba

Today, let's delve into a classic multitasking approach – the Entire Space Multi-Task Model (ESMM)1 developed by Alibaba. This model and its accompanying paper are not only straightforward and easy to comprehend but have also demonstrated remarkable effectiveness in real-world applications. Personally, I've applied this model to actual products, and it has proven to work seamlessly.
Multi-Task Learning
First, although many of you should be already familiar with multi-task learning, let’s give a brief introduction to it.
Multi-task learning (MTL) is a subfield of machine learning in which multiple learning tasks are solved at the same time while exploiting commonalities and differences across tasks.
This is the definition from Wikipedia. Here the keywords are multiple tasks, commonalities, and differences.
Multi tasks means handling several diverse tasks simultaneously. For example, predicting click through rate (CTR) and conversion rate (CVR)
Exploiting commonalities, and differences means these multiple tasks share certain similarities but also exhibit distinctions. Take the example of CTR and CVR: a user needs to click on an item, view the details, and then make a purchase. There exists a sequential dependency, where the commonality lies in the user's potential interest in the item. However, differences arise; for instance, the user might be interested but choose not to buy due to factors like high pricing or timing
Why Not Modeling Separately?
This is a common challenge encountered when constructing multi-task models, and there are primarily two reasons behind it.
Firstly, it's the cost of resources. Developing several distinct models often translates to utilizing resources multiple times over. From a cost-control standpoint, this approach is not feasible.
Secondly, there's the issue of data sparsity. In multiple tasks, it's typical to have one task with an abundance of training data, while the other tasks might have considerably less data. For example, consider the Click-Through Rate (CTR) task, which usually has a dataset two orders of magnitude larger than the Conversion Rate (CVR) task. Learning these tasks individually becomes challenging due to the significant variance in data volume. This challenge is also addressed in the ESMM paper.
Why Not Modeling the Final Target directly?
Compared to search systems, diversity and exploration are crucial in recommender systems. If we only recommend the most likely purchased items to users, we miss the chance to explore their broader interests. This limitation could negatively impact user retention; just because a user isn't interested in an item now doesn't mean they won't be in the future.
Additionally, in the advertising domain, Click-Through Rate (CTR) and Conversion Rate (CVR) are both vital metrics. Accurate predictions of CTR and CVR influence different bidding strategies. Each metric plays a distinct role in shaping advertising strategies based on user behavior.
Two Patterns of Multi-Task Learning
When building multi-task learning models, two common patterns are typically employed:
Parallel Modeling: In this approach, there is no direct dependency across different tasks, and predictions are made independently without interaction. A notable example of this pattern is the Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts (MMOE) model.
Sequential or Serial Modeling: Here, tasks have a direct dependency, and the predictions are influenced by one another. The Entire Space Multi-Task Model (ESMM) is a representative example of this sequential modeling approach
ESMM
Let's embark on the journey of learning ESMM
What Problems Does It Solve?

The first challenge is the Sample Selection Bias (SSB) problem. As shown in Fig. 1, conventional Conversion Rate (CVR) models are trained on datasets consisting of clicked impressions but are utilized to make inferences on the entire dataset, including non-clicked impressions. This inconsistency between training and inference samples leads to poor generalization, as the model struggles to accurately predict unseen samples.
The second challenge is the Data Sparsity (DS) problem. In real-world scenarios, the data collected for training CVR models is often significantly less than that available for the Click-Through Rate (CTR) task. This data sparsity makes it challenging to effectively train the CVR model.
ESMM addresses these challenges by:
Modeling CVR directly over the entire space: Unlike conventional models, ESMM directly models the Conversion Rate over all impressions, ensuring consistency between training and inference samples.
Employing a feature representation transfer learning strategy: ESMM leverages transfer learning techniques to enhance feature representation, mitigating the impact of data sparsity and improving the model's overall performance.
The Architecture
Let's delve into the architecture of ESMM, starting from the bottom and moving up. It's surprisingly simple and intuitive. On the left, we have our main target task: the Conversion Rate (CVR) task. On the right, there's our auxiliary task: the Click-Through Rate (CTR) task.
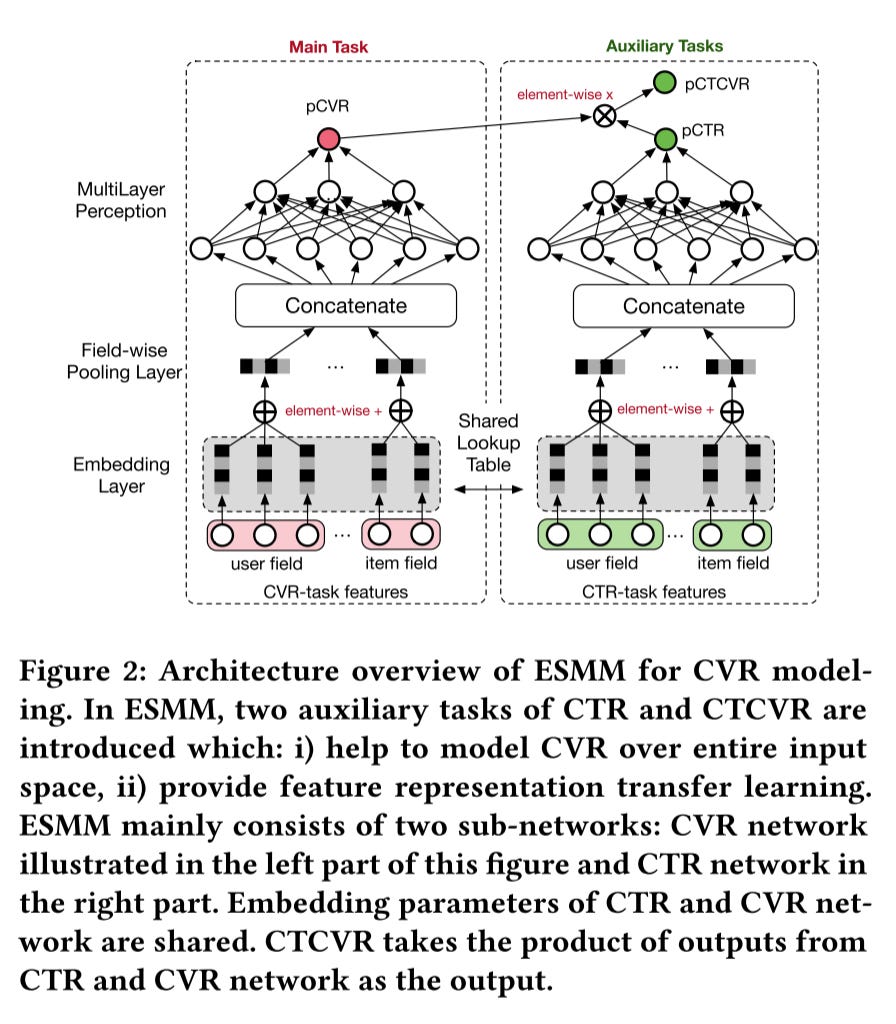
At the bottom layer, we have the input embedding layer, where the embedding tables are shared between the CTR and CVR tasks, enabling feature representation transfer learning.
Following this, a field-wise sum-pooling layer is applied on the input embeddings. While sum-pooling is commonly used, other pooling methods like average pooling or even more intricate approaches like attentive pooling on key feature fields can be explored for experimentation.
The resulting outputs from both tasks are concatenated and fed into Multi-Layer Perceptron (MLP) layers. It's important to note that the MLP layers differ between the left (CVR) and right (CTR) tasks.
The key innovation in the ESMM model lies in the output layer. Here, the CVR target is not directly modeled. Instead, it is implicitly learned by modeling the probability of Click-Through and Conversion (pCTCVR) as well as the CVR in the entire space. pCTCVR represents the scenario where a user both clicks on and purchases an item. This innovative approach allows ESMM to effectively capture CVR without directly modeling it
\(pCTCVR = pCTR * pCVR\)
Because CTR and CTCVR labels are generated for the entire space, not just the clicked space, CVR target is internally learned over the entire space.
The loss function is quite straightforward; it involves adding the Binary Cross Entropy (BCE) losses for CTR and CTCVR together. In this equation, x_i represents the input features, θ represents the model weights, and y_i and z_i represent the click and buy labels respectively. This simple yet effective approach ensures that the model effectively captures both click and conversion behaviors, enhancing its predictive power.
Experiments
I'm not surprised that ESMM outperforms all the other models. I used only the result on the product dataset with a massive 8.9 billion samples, which is substantial and sufficiently large for analysis.
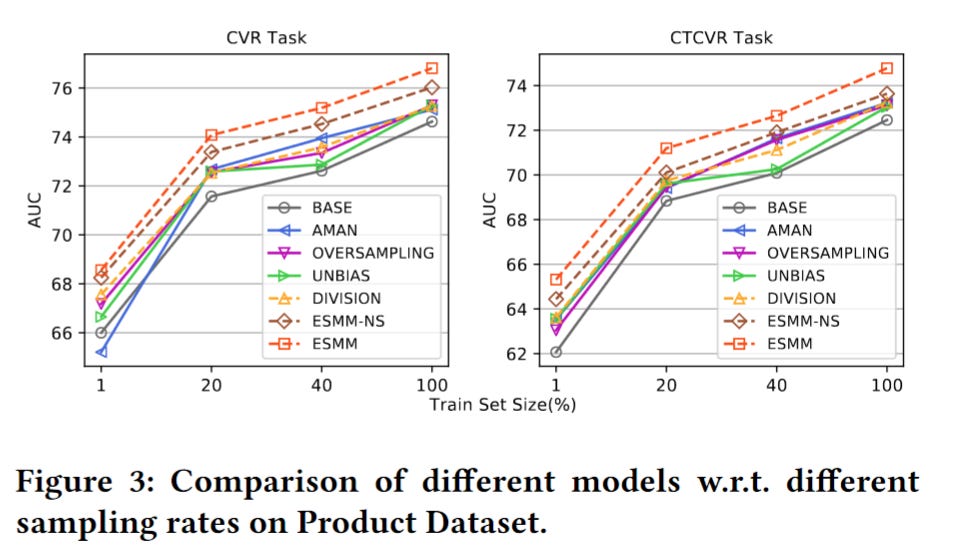
The baseline models encompass the common methods employed to address data sparsity issues and are certainly worth mentioning:
BASE is the left part of ESMM model
AMAN applies negative sampling strategy, generate negative samples from unclicked items
OVERSAMPLING copies positive examples to reduce difficulty of training with sparse data
UNBIAS follows to fit the truly underlying distribution from observations via rejection sampling. pCTR is taken as the rejection probability
DIVISION estimates pCTR and pCTCVR with individually trained CTR and CTCVR networks and calculates pCVR using pCTCTR divided by pCTR
ESMM-NS is a lite version of ESMM without sharing of embedding parameters
The Code
I created an example dataset derived from MovieLens-1M to facilitate a better understanding of the loss and model structure. In the original dataset, only samples where users had given a rated score were available. I introduced randomly sampled movies as negative samples. Then, I set the task to predict if a user rates the movie, and another task to predict if the rating is greater than 3. Therefore, the multi-task targets look like this:
Random negatives → Predict if user rates → Predict if rate > 3
The TensorFlow recommender library provides excellent support for multi-task modeling. Below, I've included my code for your reference.
First let’s define the pCTR and pCTCVR tasks. and also create the two MLP layers for each task.

Then compute the shared embeddings and generate the predicted logits for pCTR and pCVR. Then calculate the pCTCVR simply by multiplying pCTR and pCVR together. Finally, the two different loss are calculated and combined using our customized linear weights. (Linear combination is the most common way to merge multi-task losses).

Train one epoch to verify it works. We can see we have two reasonable AUC values for the two tasks.

That’s all for the ESMM model. I hope you enjoy the simplicity and effectiveness behind it. 😄
https://arxiv.org/pdf/1804.07931.pdf
thanks for this great post. I have a question:
during inference, is only CVR head used to rank items? or use CTCVR instead? or combine CVR head and CTR head(fuse both scores) together to rank items?
thanks!