

Transformer with code Part II - Encoder and Decoder
Transformer with code Part II - Encoder and Decoder
Build the encoders, decoders and put everything together

Let’s continue the tutorial on building a Transformer. For the first part, please refer to

Prepare Training Data
To verify the performance and correctness of our version of Transformer. Let’s follow the tutorial from the official TensorFlow blog and prepare a training dataset for the translation task. You can check my Jupyter code here.
This is a Portuguese-English translation dataset Containing approximately 52,000 training, 1,200 validation, and 1,800 test examples. We can use the TensorFlow dataset library to load it directly.

Check a few examples.

TensorFlow already provides two tokenizers for the two languages. Let’s use it directly. We can see they provide the necessary functions like tokenize and detokenize. We can also get the vocabulary size using the get_vocab_size function.
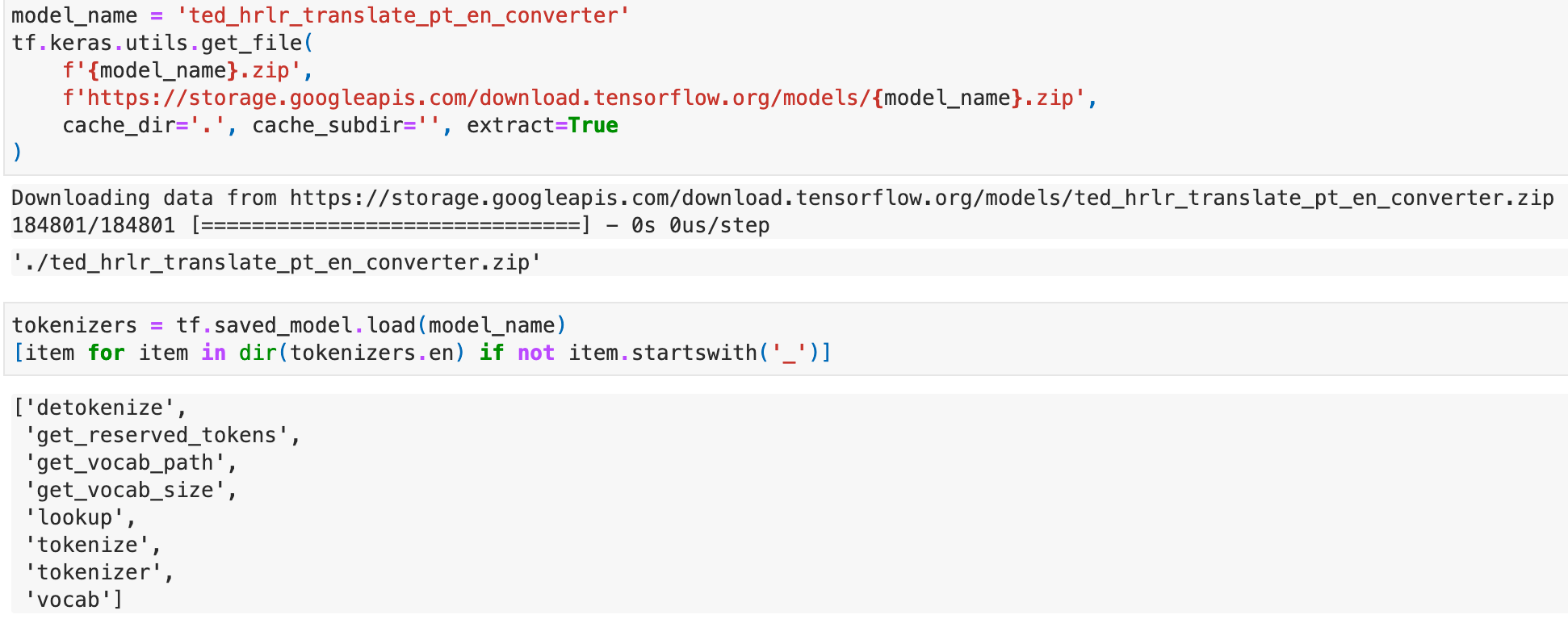
After tokenizing, the words are mapped into integer tokens for the purpose of lookup in Embedding tables.

Besides segmentation, two special tokens [Start] and [End] are inserted at the start and end of the English sentence. For the reason, please refer to this section.

Let’s define a custom function to convert, trim, and pad the original words to real training samples. Notice here, that one training sample consists of 3 parts, Portuguese tokens as the input for the Encoder, English tokens as the input for the Decoder, and shifted English tokens as the labels.
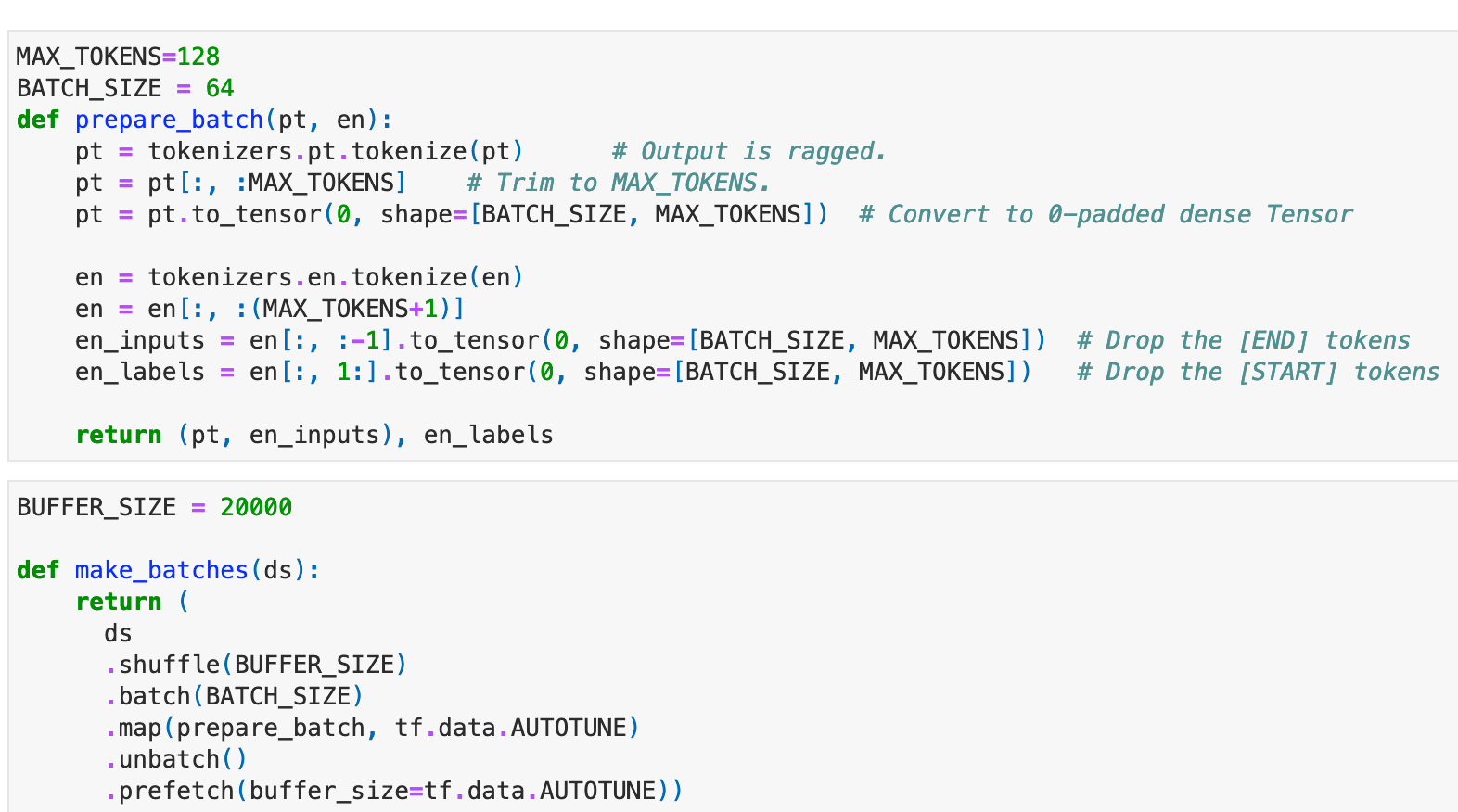
Notice here that the label is shifted one step to the right based on the English tokens.
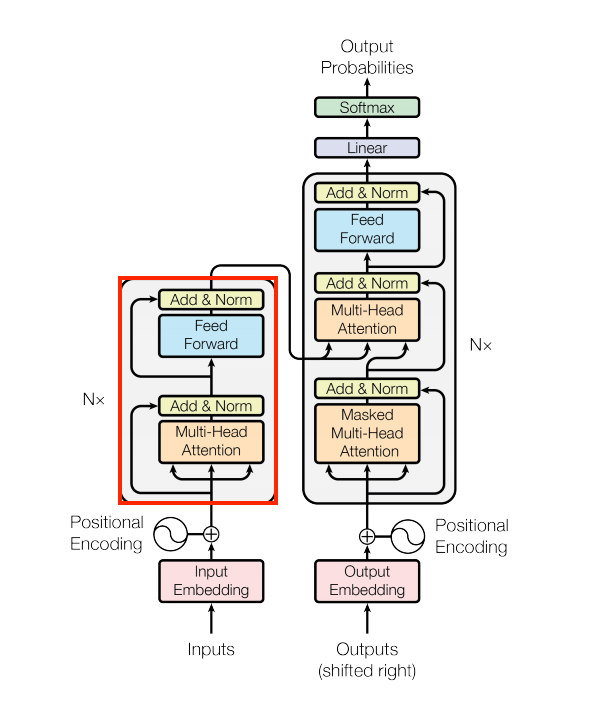
Building the Encoder
The Encoder is composed of a feed-forward module and a self-attention module with extra residual and normalization connections. All the codes can be found here.
Build the Feed Forward Layer
The feed-forward layer is simple. But please notice two things:
To appropriately propagate masks, we must use the Add layer from Keras. At first, I used a + operator, but it failed to handle the masks. (Dark side of TensorFlow 😅)
The Dropout layer is put before the add and normalization operation. In the original paper, the explanation regarding the specific placement of the dropout layer lacks clarity and detail.

Assembly the Encoder
Define the encoder layer, according to the original paper, the key_dim is extracted from model_dim divided by head_num. So even if we increase the number of heads, the total parameter number won’t change.
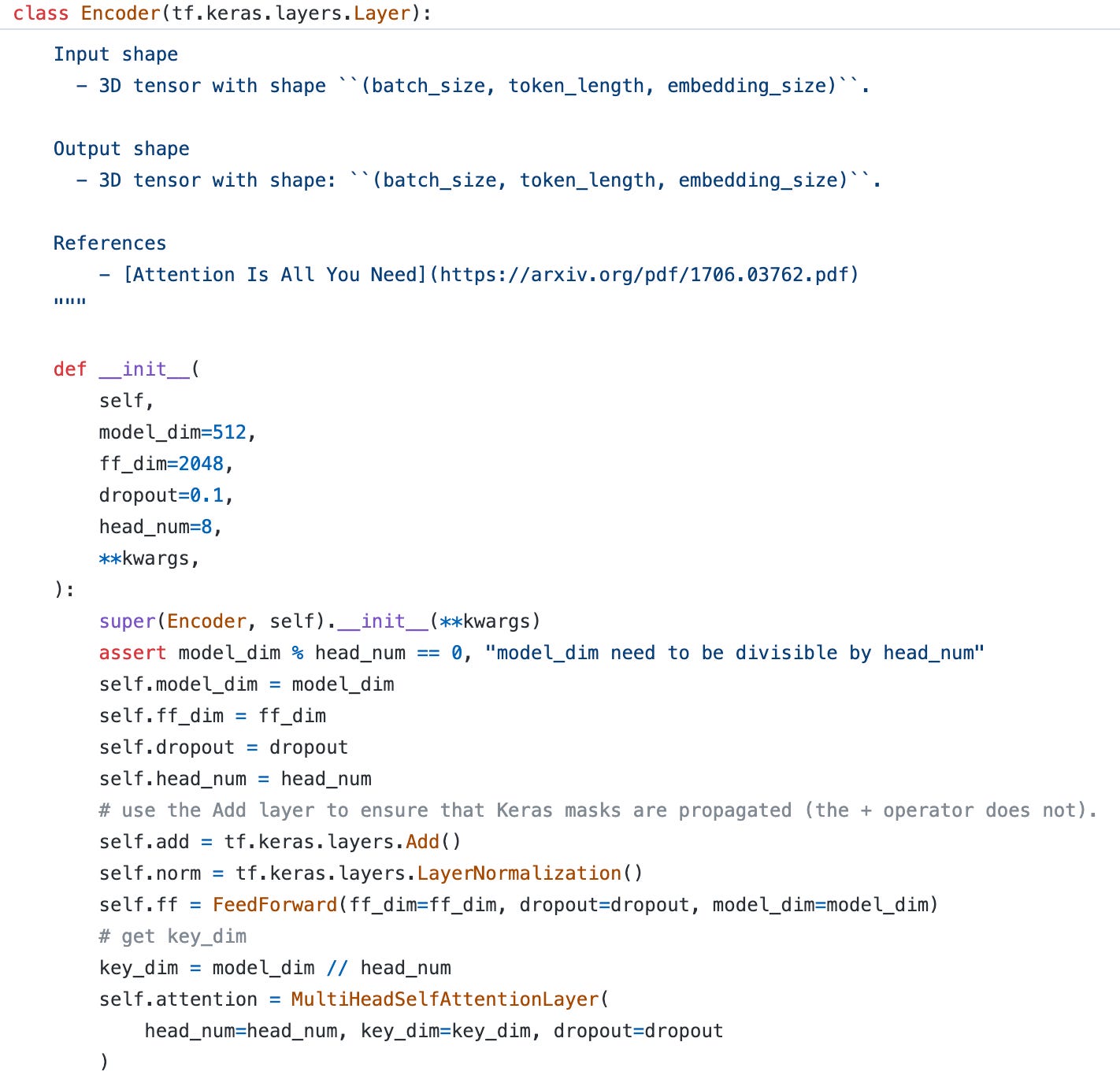
The call function is simple, just stack the attention layer and feed-forward layer together. Notice that there is only one input for the encoder, which is the Portuguese token embeddings. The input query, key, and value all come from these token embeddings.

Build the Decoder
The decoder consists of one self-attention layer, one cross-attention layer, and one feed-forward layer with extra residual and normalization connections.
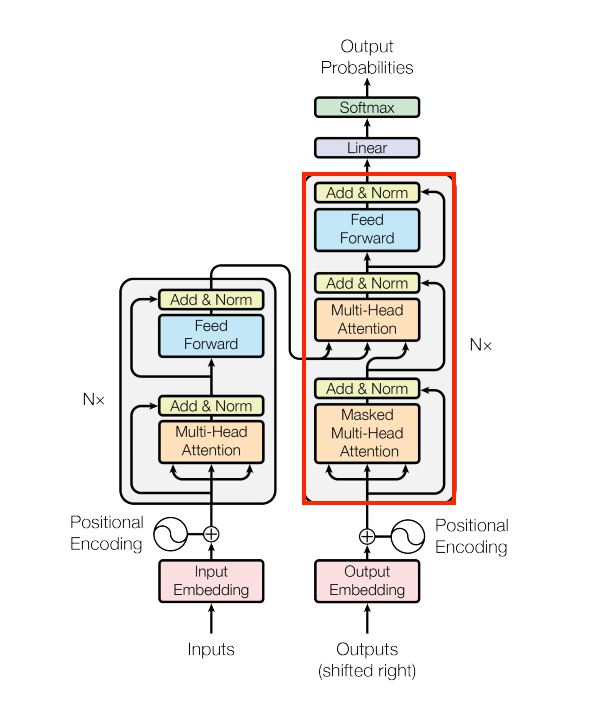
Define all the components we need.

In the call function, for the first self-attention layer, the input is all from the English token embeddings and a casual mask should be used to prevent information leaking.
For the second cross-attention layer, the query is from the previous attention layer output. The key and value are from the encoder output.

Build the Transformer
Let’s put all the components together and define a Transformer model. Notice that there is a dropout layer after the positional embedding layer. And there is a final dense layer to convert the embeddings to softmax scores. The dimension of scores is the target vocabulary size, here is the English vocabulary size.


Adaptive Learning Rate
In the paper, the author uses an adaptive learning rate defined as:
And the warmup_steps is 4000. For the steps below warmup_steps, the right part of the min operator is smaller, so the learning rate will increase gradually. For the steps after warmup_steps, the left part becomes smaller. then the learning rate will decrease gradually. The figure is shown below.

Why need warmup? My thought is at the beginning steps, we need to take some time to find the best direction for gradient descent. After a few warmup steps, we are confident that a larger learning rate can be used.
Customize Loss and Metrics
To handle masks in the inputs (ignore the masked tokens), we need to customize the loss and metrics. Here I use the official implementation from TensorFlow. The only difference is that I turn the from_logits parameter to False because we already apply the softmax in the final dense layer before.

Training
The hyperparameters I used are listed below. Notice that in the TensorFlow tutorial. The key_dim is the same as the model_dim. But in my implementation, the key_dim is the result of model_dim divided by head_num.

Train it on the dataset we prepared before. The result is close to the that in TensorFlow tutorial.
810/810 [==============================] - 168s 189ms/step - loss: 6.3818 - masked_accuracy: 0.1428 - val_loss: 5.0241 - val_masked_accuracy: 0.2425
Epoch 2/20
810/810 [==============================] - 139s 170ms/step - loss: 4.7336 - masked_accuracy: 0.2647 - val_loss: 4.3481 - val_masked_accuracy: 0.3062
Epoch 3/20
810/810 [==============================] - 139s 171ms/step - loss: 4.0566 - masked_accuracy: 0.3381 - val_loss: 3.6400 - val_masked_accuracy: 0.4031
Epoch 4/20
810/810 [==============================] - 139s 171ms/step - loss: 3.4288 - masked_accuracy: 0.4125 - val_loss: 3.1637 - val_masked_accuracy: 0.4598
Epoch 5/20
810/810 [==============================] - 139s 171ms/step - loss: 2.9653 - masked_accuracy: 0.4668 - val_loss: 2.8408 - val_masked_accuracy: 0.5029
Epoch 6/20
810/810 [==============================] - 139s 171ms/step - loss: 2.5941 - masked_accuracy: 0.5140 - val_loss: 2.5317 - val_masked_accuracy: 0.5422
Epoch 7/20
810/810 [==============================] - 139s 171ms/step - loss: 2.2883 - masked_accuracy: 0.5556 - val_loss: 2.4011 - val_masked_accuracy: 0.5649
Epoch 8/20
810/810 [==============================] - 139s 171ms/step - loss: 2.0660 - masked_accuracy: 0.5871 - val_loss: 2.2967 - val_masked_accuracy: 0.5790
Epoch 9/20
810/810 [==============================] - 139s 171ms/step - loss: 1.8972 - masked_accuracy: 0.6116 - val_loss: 2.2173 - val_masked_accuracy: 0.5919
Epoch 10/20
810/810 [==============================] - 139s 171ms/step - loss: 1.7575 - masked_accuracy: 0.6328 - val_loss: 2.1792 - val_masked_accuracy: 0.5996
Epoch 11/20
810/810 [==============================] - 139s 171ms/step - loss: 1.6355 - masked_accuracy: 0.6518 - val_loss: 2.1533 - val_masked_accuracy: 0.6071
Epoch 12/20
810/810 [==============================] - 139s 171ms/step - loss: 1.5325 - masked_accuracy: 0.6677 - val_loss: 2.1390 - val_masked_accuracy: 0.6104
Epoch 13/20
810/810 [==============================] - 139s 171ms/step - loss: 1.4392 - masked_accuracy: 0.6822 - val_loss: 2.1320 - val_masked_accuracy: 0.6130
Epoch 14/20
810/810 [==============================] - 139s 171ms/step - loss: 1.3567 - masked_accuracy: 0.6957 - val_loss: 2.1213 - val_masked_accuracy: 0.6174
Epoch 15/20
810/810 [==============================] - 139s 171ms/step - loss: 1.2841 - masked_accuracy: 0.7076 - val_loss: 2.1441 - val_masked_accuracy: 0.6150
Epoch 16/20
810/810 [==============================] - 139s 171ms/step - loss: 1.2148 - masked_accuracy: 0.7194 - val_loss: 2.1457 - val_masked_accuracy: 0.6192
Epoch 17/20
810/810 [==============================] - 139s 171ms/step - loss: 1.1525 - masked_accuracy: 0.7299 - val_loss: 2.1673 - val_masked_accuracy: 0.6181
Epoch 18/20
810/810 [==============================] - 139s 171ms/step - loss: 1.0949 - masked_accuracy: 0.7405 - val_loss: 2.1910 - val_masked_accuracy: 0.6147
Epoch 19/20
810/810 [==============================] - 139s 171ms/step - loss: 1.0439 - masked_accuracy: 0.7490 - val_loss: 2.2028 - val_masked_accuracy: 0.6176
Epoch 20/20
810/810 [==============================] - 139s 171ms/step - loss: 0.9956 - masked_accuracy: 0.7577 - val_loss: 2.2167 - val_masked_accuracy: 0.6145Weekly Digest
Effective > Productive. Productivity is for machines, not for people.
Vented interstage and heat shield installed atop Booster 9. Starship

Do Machine Learning Models Memorize or Generalize? An interactive article that introduces the concept of grokking

Is Meta-Learning the Right Approach for the Cold-Start Problem
in Recommender Systems? When tuned correctly, standard and widely adopted deep learning models perform just as well as newer meta-learning models
Experimentation at Spotify: Three Lessons for Maximizing Impact in Innovation
Start with the decision that needs to be made.
Utilize localization to innovate for homogeneous populations.
Break the feature apart into its most critical pieces.

Thanks for this great post.
I think the dropout layer is missing in residual connection in both encoder and decoder in this implementation.
```
attention_output = self.norm(
self.add(
[input, dropout(self.attention(input, input, input, training=training)) ],
),
training=training,
)
```