
Two tower candidate retriever I
Bias correction for in-batch negative sampling

In this post, I will go through the classic two tower paper from google, aka Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations1, and show a concrete implementation example from TensorFlow Recommender.
Paper reading
Abstract
In the abstract, the author brings the issue we meet in industry recommendation system, retrieving and scoring items from a very large corpus. One common recipe to train a two-tower model is to learn the user and item representation and calculate loss functions from in-batch negatives. But in-batch loss is subject to sampling bias, especially in a highly skewed data distribution which is very common in industry. So the author bring a novel algorithm to estimate the item frequency from streaming data and verify the performance on YouTube.
Key points:
Very large corpus, makes it impossible to calculate a full softmax for all items in the corpus. Negative sampling is a must
Estimate from streaming data, this means the algorithm can adapt to the change of item frequency and be applied to real-time model training which is critical for modern recommender systems
Introduction
In this part, the author revisits the history of recommendation models and give a short introduction on two-tower model which is good at modeling <user, context> and <item> relationships, and incorporating rich user, item features.

As illustrated above, the left tower is a user tower, which normally input with user, context features, ingest these features with several layers of MLP and output the user vector. The right tower is a item tower, input with item content features and it has the same structure as the user tower.
The two-tower model is generalized from MLP models, like the YouTube DNN2.
For the MLP models:
they are trained with many sampled negatives from the whole corpus
the item tower is simplified to a single layer with item embeddings. So it's fast to train
But for two-tower model:
the item tower is much more complex
not feasible to have a large amount of negatives
In batch softmax as the common solution, calculate the probability in a single batch
But in bach softmax is subject to sampling bias. Then the author bring up a novel algorithm to solve this issue.
Related work
In this part, the author mainly talks about the framework of two-tower model and explains the algorithm.

Because we are using in-batch negatives and the power-law distribution, the popolar items are over penalized. The logits need to be corrected by LogQ correction.

Normalization and Temperature
They found emperically, the performance can be improved by adding a normalization embedding normalization layer and a temperature hyper-parameter to scale the logits.
My comment 🤔: In my experience, this 2 params do have a big impact on the final performance, around 5% improvement on the recall rate metrics.
Streaming frequency estimation
In this part, the author gives a math proof of the algorithm and describe the steps.
δ denotes the average number of steps between two consecutive hits of the item.

And they also prove that with as t → ∞, the bias will be 0. And the variance is limited by

Regarding the learning rate α
higher rate causes a faster decrease of the first term that depends on initialization error — converge faster, but be affected higher by the variance
lower rate reduces the second term which depends on the variance of ∆ and does not decrease over time — converge slower
They also consider the hash collision and bring another upgraded algorithm 3 using multible hash functions. Then they take the maximum of multiple estimations representing the number of steps between two consecutive hits.

Neural retrieval system for YouTube
In this part, the author shares the detailed model structure and training strategy for YouTube
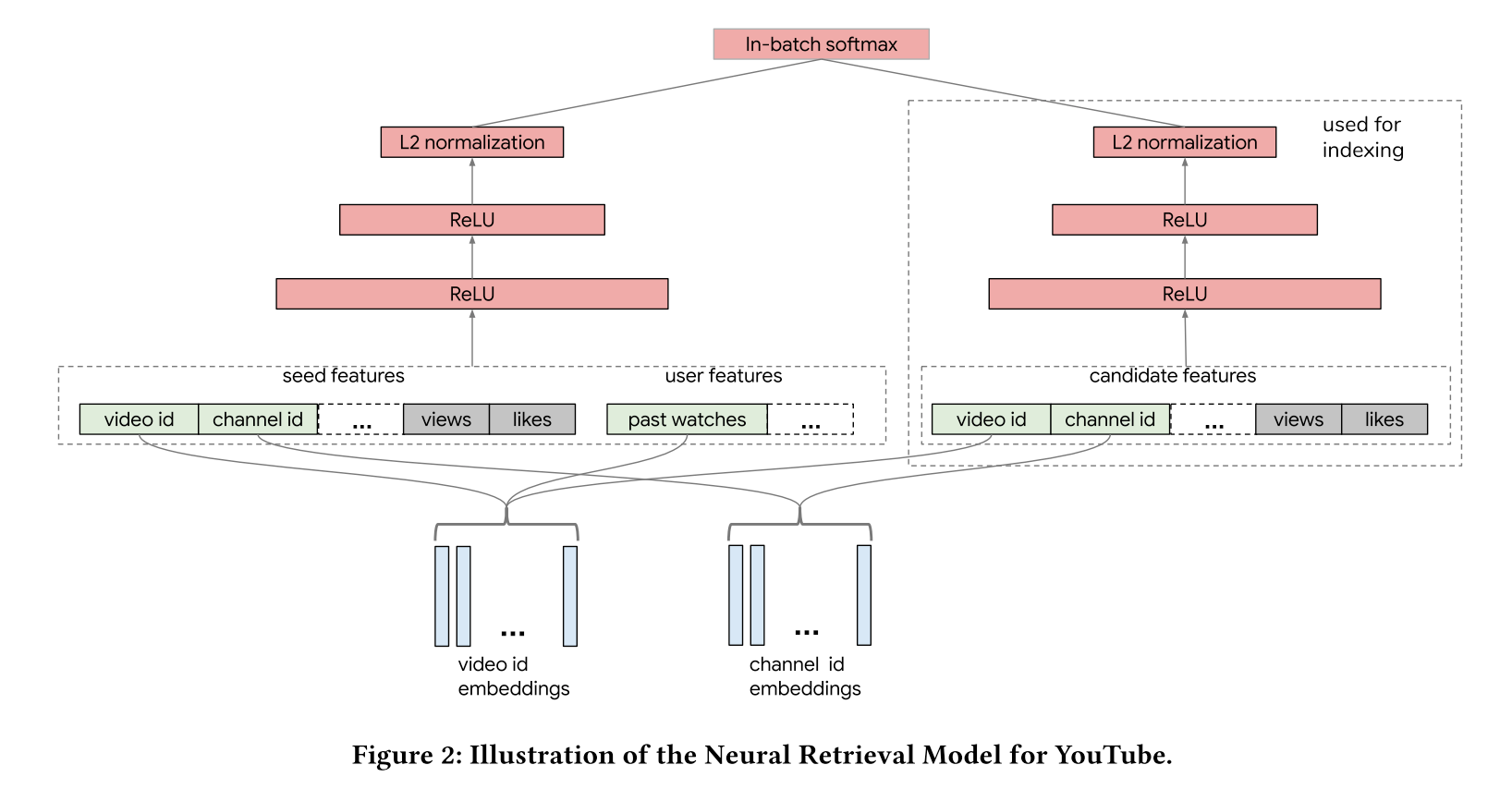
Training label, click weighted by watching complete ratio
Video features
Dense features, normalization
Categorical features
One value, like video ID, one embedding as the representation
Multiple values, like topic IDs, weighted sum of embeddings
Out-of-vocabulary entities, randomly hashed to a bucket
User features
Current watching video as the seed video features, same features shared with item tower
Watch histories, average of the video embeddings
Embedding features are shared between the two tower
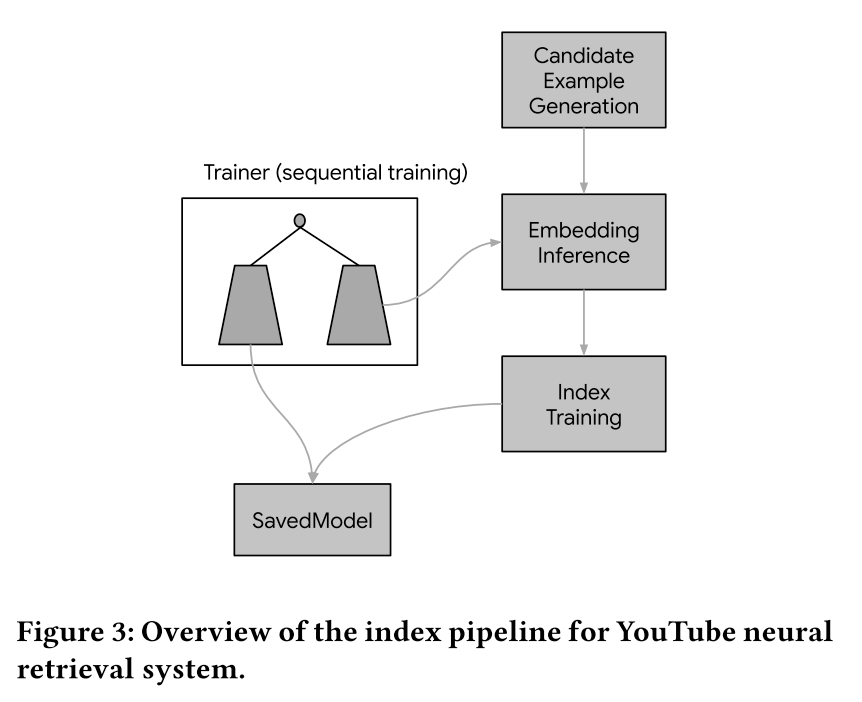
The training data is generated on a daily basis and feed into the trainer. The serving part is separated into 4 stages:
Select candidate video set based on the their business requirement
Use item tower to generate embeddings for all candidates
Train the index model for the generated embeddings, here probably they are using Google’s ANN library Scann3
For the last stage, they save the user tower together with the trained index and serve them online. My comment 🤔:
In traditionally approach, people usually separate the user embedding online inference from the candidate index building
The user tower will be saved and served for online real-time inference
The item tower will be used for offline index generation. Then the index will be deployed separately for online search. This can be done leveraging ANN library like Faiss 4
This approach has a consistency issue, there is a time gap between deploying user tower and index. This can be solved by add an additional version tag for both user and index model. When querying, specify the corresponding model using the tag. But this still bring more complexity
In this paper, they avoid this issue by save and serving user and index model together. There is a concrete example in TensorFlow Recommender library
Experiments
In this part, the author conducts a few experiments to verify the performance of sampling bias correction. I picked the 2 most important tests here.
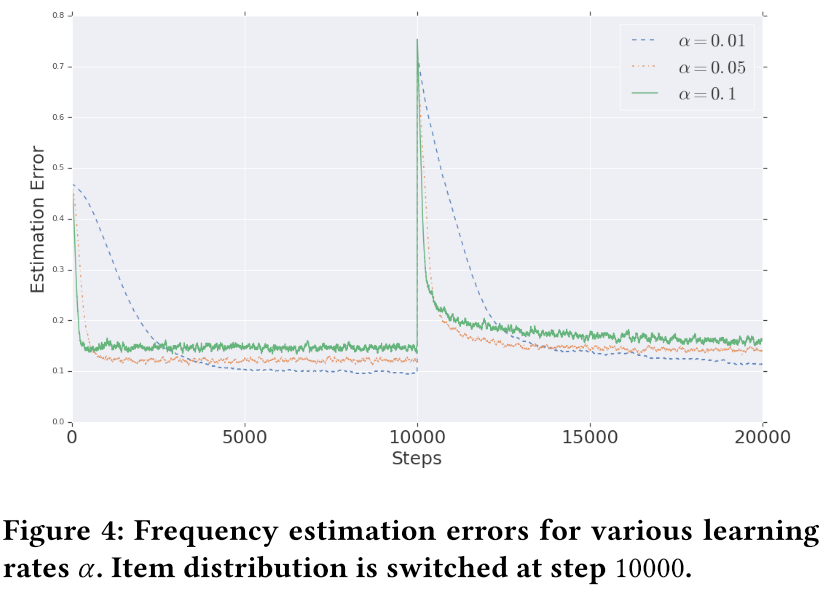
Simulation on frequency estimation
With a higher learning rate, the algorithm is more adaptive to distribution change, but the final variance is higher.
YouTube Experiments
Model structure:
three-layer DNNs with hidden layer sizes [1024, 512, 128] for both
towerstrain the model using Adagrad, learning rate 0.2, and batch size 8192. My comment 🤔: Interesting to see they use a huge batch size with a large learning rate, guess the model size is not very big
for frequency estimation, they set H = 50M, m =1, α = 0.01
index of approximately 10M videos (this is large, need to use approximate search algorithm) chosen from the YouTube corpus is built periodically every few hours (few hours is not even near real-time, I guess this is because the engagement growth of new video is slower compared to news scenario)
Model training:
15 days data training as the warm up phase
10% data for evaluation
average 7 days results after the first 15 days
for in batch softmax, the offline result is significantly better than mse baselins (I doubt why choose this as the baseline, it’s quite weak)
corrected softmax is also significantly better than plain softmax

Online ab test:
for control group, no change. My comment 🤔: it will be much better if they share the details of the control settings
for treatment group, add the new model as a new candidate retriever
both versions show significant gain

Build a frequency estimation layer
Let’s build the sampling bias correction layer leveraging the experimental API from TensorFlow.
In the paper, they use a fixed length array to record the steps, then use hash functions to map the keys to the array index. Actually this is equivalent to a hashmap. Now TensorFlow provides the DenseHashTable and MutableHashTable data structure, we can build the algorithm on it.
Quick comparison between these 2 hash tables:
DenseHashTable offers generally faster
insert,removeandlookupoperations, in exchange for a higher overall memory footprint. This is because it has an aggressive momery allocation strategy . And it uses "open addressing" with quadratic reprobing to resolve collisionsMutableHashTable uses the standard C++ hash table API. So it doesn’t need to specify
empty_keyanddeleted_keyIn this case, I prefer faster query than memory consumption because in general we want to train faster. So I choose DenseHashTable
Here is the code
class SamplingBiasCorrection(tf.keras.layers.Layer):
"""A naive implementation of SamplingBiasCorrection.
It supports the basic step estimation operation and returns the sampling probability for each key.
Notice it doesn't support key expiration yet, so the memory will continue to grow if used in sequential training.
"""
def __init__(self, lr=0.05, **kwargs):
"""Use one table to record the lastest step, aka the A table in paper
Use another table to record the estimated step gap for each key, the B table in paper
"""
super(SamplingBiasCorrection, self).__init__(**kwargs)
self.lr = lr
self.lastest_step = tf.lookup.experimental.DenseHashTable(
key_dtype=tf.string,
value_dtype=tf.int64,
default_value=0,
empty_key="",
deleted_key="$",
)
self.step_gap = tf.lookup.experimental.DenseHashTable(
key_dtype=tf.string,
value_dtype=tf.float32,
default_value=0,
empty_key="",
deleted_key="$",
)
def call(self, cur_step, candidate_ids):
cur_step = tf.repeat(cur_step, tf.shape(candidate_ids))
latest_step = self.lastest_step.lookup(candidate_ids)
previous_gap = self.step_gap.lookup(candidate_ids)
# if it's the first time meet this sample, then turn the lr to 1.0
cur_gap = (1 - self.lr) * previous_gap + tf.where(
latest_step == 0, 1.0, self.lr
) * tf.cast(cur_step - latest_step, tf.float32)
self.lastest_step.insert(candidate_ids, cur_step)
self.step_gap.insert(candidate_ids, cur_gap)
return 1 / cur_gapTo use it, we need to create a global step counter to record the current training step. Then feed it to this layer in the training process.
def compute_loss(self, inputs, training=False) -> tf.Tensor:
if training:
self.global_step.assign_add(1)
candidate_sampling_probability = self.sampling_bias(
self.global_step, candidate_ids
)Then the correction will be made before feed into softmax.
class SamplingProbablityCorrection(tf.keras.layers.Layer):
"""Sampling probability correction."""
def __call__(self, logits: tf.Tensor,
candidate_sampling_probability: tf.Tensor) -> tf.Tensor:
"""Corrects the input logits to account for candidate sampling probability."""
return logits - tf.math.log(
tf.clip_by_value(candidate_sampling_probability, 1e-6, 1.))I tested the implementation in a real production model, it can achieve a similar performance as the uniform pre-sampling before training. The training speed will be 10x faster because all the samples are taken as the negatives for each other and all the similarity calculation can be easily done with fast matrix multiplication.
What’s next
The implementation is not perfect. In real world, if the corpus is super huge and continually to grow, the memory consumption will be intolerable. I will upgrade this naive approach to support expiration functions, i.e. expire the old keys and clean the memory footprint.
In-batch negative sampling has problems too. The major issue is long-tail content can not been learn comprehensively because the samples are dominated by popular items. In next post, I will share another paper that tackle this issue using mixed sampling strategy.
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/6c8a86c981a62b0126a11896b7f6ae0dae4c3566.pdf
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45530.pdf
https://github.com/google-research/google-research/tree/master/scann
https://github.com/facebookresearch/faiss
Fan, can you share your experiment setup when you say "this 2 params do have a big impact on the final performance, around 5% improvement on the recall rate metrics."? The reason of this ask is that I failed to make them work in my experiment setup, which is: (1) each tower is just an embedding lookup table (2) feature is just user id and movie title (3) movielen_100k dataset. There are two variants: (1) sampling bias correction as the baseline (2) baseline + l2 + temperature. I used kerastuner to tune the learning rate and temperature. However, I can't make the variant 2 (baseline + l2 + temperature) outperform variant 1 even with extensive tuning. Here is the colab link in case you are interested: https://drive.google.com/file/d/1i3suC8hE0zK3p5slM5TQKlzSjvMLtsqK/view?usp=sharing. I wonder if it's due to the model is too simple and the dataset is too small.
thanks for the great explanation, it answers many questions about the streaming frequency estimation in my mind for years. There is still one more puzzle for me and can you help me confirm my understanding: it's definitely possible that a batch contains the same item multiple times and all of those duplicated items in the same batch have the same item frequency estimation?