
Two tower candidate retriever III
Upgrade the bias correction implementation

In this article, I will solve another issue I mentioned in the previous article. Enhance our naive approach of sampling bias correction with expiration function.
In real world, if the corpus is super huge and continually to grow, the memory consumption will be intolerable. I will upgrade this naive approach to support expiration functions, i.e. expire the old keys and clean the memory footprint.
Design choice
Requirements
Suppose we have a endless streaming training data and the corpus is always increasing. This will lead to the endless memory growth issue, we need to solve it by expire useless keys. How to define useless:
LFU (Least Frequently Used), only keep the recent N items
Time window, expire all the keys older than a certain time window ( current_time - time_window)
Since by default, the training data is iterated by steps, it doesn’t contain the concrete timestamp information. So let’s focus on the first approach here.
Unload factor
As the design in HashTable, it has a implicit load factor (a measure that decides when to increase the HashTable capacity to maintain the search and insert operation complexity of O(1)) . In most languages, it’s default to 0.75.
Here we can borrow the similar idea, define a unload factor - a measure that decides when to decrease the HashTable capacity to maintain the vocabulary size below capacity. Here I set the default value to 1.25, as the reverse to 0.75. Every time the current vocabulary size reachs 1.25*capacity, it will trigger an cleaning operation.
Notice this factor cannot be too small, frequently cleaning will bring extra cost.
MutableHashTable
Previously I prefer DenseHashTable other than MutableHashTable because the DenseHashTable provides faster lookups and higher memory usage. And in most case we care training speed much more than memory usage.
But after I tried to implement the expiration function, I found it’s super trivial if I use DenseHashTable. Because its aggressive memory allocation strategy and open addressing hash collision resolving approach, I have to handling extra tons of unused keys and filter out them while clean the expired keys. So here I replace it with the MutableHashTable for simplicity.
Implementation
I put the code here.
For initialization part, we need to specify the desired capacity and unload factor. Then the upper_threshold_capacity will be calculated from these 2 parameters.
How to choose the right capacity? There depend on your business requirement.
You can estimate your vocabulary size in a certain time window, like the total item number in recent week

Then there is the cleaning logic, expire keys based on LFU.

At last, trigger it in call function.

That’s it. Let’s run a simple test. We can see all the old keys have been cleaned.

Train on MovieLens
The dataset is movielens_1m, the total movie vocabulary size is around 6k.
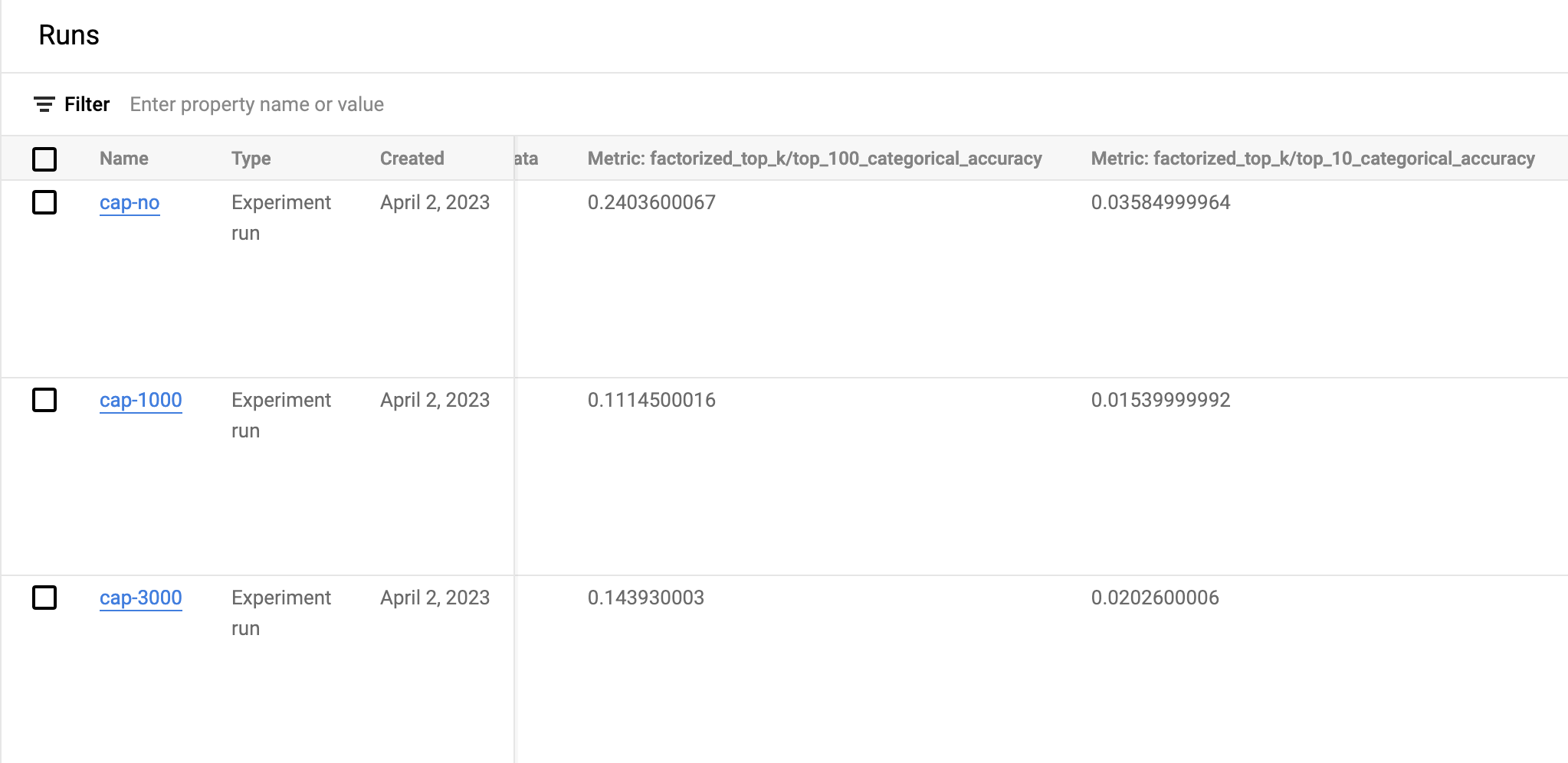
Let’s try different capacity settings, same unload factor 1.25 and simply run 1 epoch for prototype verification:
cap-1000, this will trigger cleaning operation almost every training step
cap-3000, trigger less frequently with a bigger vocabulary
cap-no, default to 2**17=131072
Performance comparison on recall rate, collected from Vertex AI. We can see that cap-no has the best result because it covers all the keys and correct all the bias. cap-3000 is the second and cap-1000 is the worst.
Weekly digest
From this week, I will add a new section providing the informative articles I find.
Tensorflow 2.12 is released. Key points:
Keras new model export formats
keras.utils.FeatureSpace utility. It enables one-step indexing and preprocessing of structured data – including feature hashing and feature crossing. Feature crossing function is officially included in TensorFlow now 🚀
Twitter opens its recommender system code and shares the details in their blog . Some intial findings
What’s next
I have finished the major part of two tower candidates, from now on I will revisit several classic recommendation papers and show the concrete implemenation build from scratch.