
Two tower candidate retriever II
Mixed negative sampling

In this post, I will go through another paper, Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations1. It propose a novel approach to solve the issue I mentioned in the last post.
In-batch negative sampling has problems too. The major issue is long-tail items can not been learn comprehensively because the samples are dominated by popular items.
Paper reading
Abstract
In this part, the author introduces their work of applying two-tower model to the app recommendation system for google play store. The problem is quite similar to the Youtube system, efficiently retrieving top k items given user’s query from deep
corpus. And they offer a novel negative sampling approach called Mixed Negative Sampling (MNS).
Key points:
Mixed Negative Sampling (MNS), a mixture of batch and uniformly sampled
negatives to tackle the selection bias of implicit user feedbackOnline abtest shows it performs better than in-batch negative sampling with bias correction. This is different from the result in the sampling bias paper. My comment 🤔: it’s because, compared to Youtube, the user actions in google play store is highly skewed, i.e. most installs come from the top apps. So the bias is more serious
Introduction
First, a short introduction on the history of two-tower framework. We are already familiar with it, let’s skip this part.
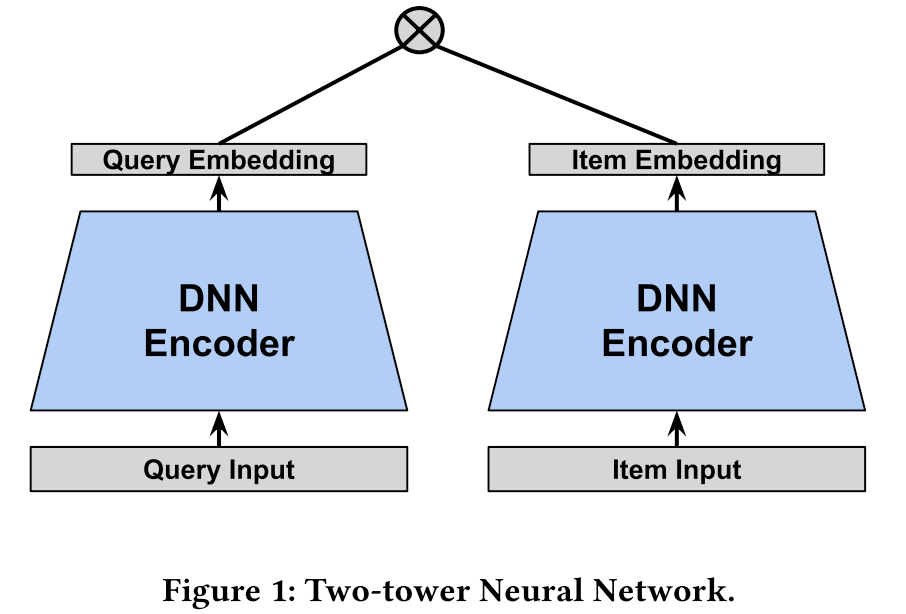
Then it goes to the core idea of MNS.
Unigram-sampled2 or batch negatives have the limit of selection bias in training data
Accordingly, sampling batch negatives only from training data will end up with a model lacking resolution for long-tail apps, which seldom appear in the training data
MNS is a mixed sampling strategy, combine unigram with batch negative sampling
reduce selection bias by bringing in samples from the entire candidate corpus
adjust the sampling distribution by changing the number of additional negative samples from the corpus
My comment 🤔: the second point brings us another problem. What’s the ideal sampling distribution for candidate retriever?
empirically we can follow the practice from the word2vec paper3
for positive samples, P(wi) is the probability of keeping the word

wi is the word, z(wi) is the fraction of the total words in the corpus that are that word for negative samples, the best power is 3/4

f(wi) is the same as z(wi) in practice, the in-batch sampling part cannot be controlled, but we can tune the unigram sampling distribution to achieve the target distribution


The major contributions:
Real-world application
Mixed negative sampling
Offline and online experiments, extensive offline and online experiments in Google Play to demonstrate the effectiveness of MNS
My comment 🤔: point 1 and 3 should be done in everything industry paper. Point 2 is the real contribution
Related Work
The author claims they are the first to consider the selections bias brought by in-batch negative sampling.
Modeling Framework
This picture shows the implementation of in-batch negative sampling:
Query embedding as the user embedding, item embedding as the content embedding
For each positive sample as the corresponding row in the picture, take other items as the negative samples. Run a matrix multiplication, then we can get the positive and negative logits for each query
Build a identity matrix, the diagonal line will be the positive labels
This approach can significantly speed up training, because the matrix operations are optimized by modern hardware and software. But the distribution will follow the unigram distribution on item frequency

The problem of following unigram distribution is:
Selection bias. the model lacks capability to differentiate items with sparse feedback w.r.t other items. Sparse feedback leads to low training chance, especially long-tail items
Lack of flexibility to adjust sampling distribution. As I mentioned before, we often need to tune the sampling distribution, like to downweight popular items
Here comes the solution, it’s actually quite straightforward:
Besides the in-batch samples, add another uniformly sampled data stream, which is a set of composed items from the entire corpus
Append these item embeddings to the original batch, then the logits will contains the extra values
For the labels, we can simply append zero columns, represent all the newly added items are negatives
This turns into a mixture (MNS) of item frequency based on uniform and unigram sampling and the ratio between these two can be tuned

How MNS solved the two issues above?
Reducing selection bias: all items in the corpus have a chance to serve as negatives so that the retrieval model has better resolution towards fresh and long-tail items
Enabling more flexibility in controlling sampling distribution: the effective sampling distribution Q is a mixture of item frequency based unigram distribution from training data and uniform distribution from index data
My comment 🤔: actually, the newly added stream can be any distribution. For example, if we want to down boost popular items, we can modify the stream to have more popular items.
Question here, should we do bias correction if we intentionally downboost popular items?
The answer is no, if we correct the bias, the sampling distribution will be ignored
Case study
As we can see here, the recommendation system for Google Play is similar to Youtube.
One thing worth mention is the training data is constructed from logged user implicit feedback in the form of {query, candidate app} pairs, where candidate app is the next app which user installed from recommended apps. So the target is given the user, context and seed app information, predict the next most likely installed app.


Experiment results
Data collection:
30 days logged data, evaluate on the next 7 days and calculate the average metric. My comment 🤔: notice the time window is twice bigger than that in Youtube which is 15 days, this is probably because app installation actions are sparser than video watch. So here we need longer time to collect data
Baseline establishment:
MLP + sampled softmax without content features. This is the orginal setup from YoutubeDNN paper4
Two-tower DNN with in-batch negative sampling. This is the setup from sampling bias correction paper
Two-tower DNN with MNS
It is worth noting that the two-tower and MLP models have roughly the same number of model parameters, this is a fair comparison
Effective sample size is 2048 for all the 3 models
Adagrad as optimizer with learning rate at 0.01. ReLU is used as activation function for all hidden layers
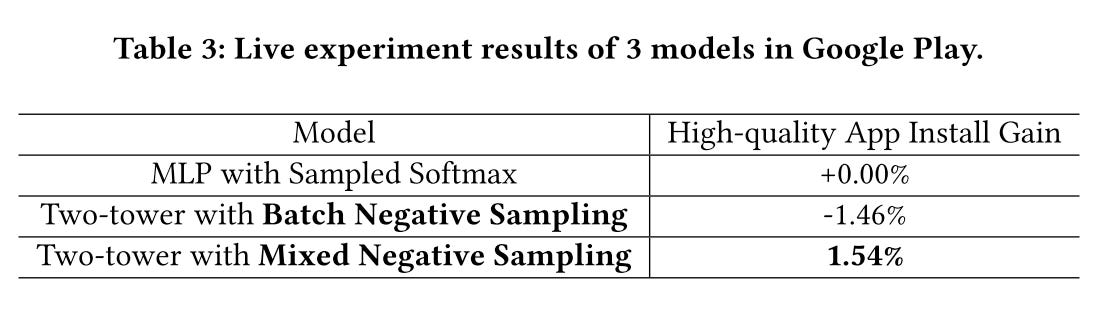
Performance:
In-batch negative sampling is worse than MLP with sampled softmax, and observed quite a few irrelevant tail apps in the retrieval results. This prove in-batch negative sampling suffers from selection bias, long-tail apps don’t appear as negatives enough
MNS performs the best as expected

Hyper-parameter tuning on index data batch size:
The model performs best when the batch size is 8192
But when having larger B', the result turns to be worse. According to the author
It leads to a sampling distribution too close to the uniform distribution.
It deviates from the desired serving time distribution and thus hurts the model quality
How to understand this? My comment 🤔:
We want a model that have a good resolution on both the popular items and long-tail items
If the sampling distribution is too close to the uniform distribution, then the popular items can easily win because of their intrinsic popularity. The retrieval results will be dominated by them
If the sampling distribution is too close to unigram distribution, then the popular items will be down boost too much as they are frequently chosen as the negatives
So here is an internal balance requirements between these two sampling streams

Online ab testing
AB testing for 2 weeks, this is almost a standard for industry.
The interesting thing here is how Google define their online metric, high-quality app install. They define it as the number of apps that users actually used after installing, as opposed to uninstalling within 1 day or having no usage. Basically this filters out fake installs.
Implement MNS
Instead of generate the negatives while training, we can concatenate two streams together can feed them to the training function.
train = self.train_data.batch(self.hparams.batch_size).cache()
test = self.test_data.batch(self.hparams.batch_size).cache()
uniform_negatives = (
self.candidate_data.cache()
.repeat()
.shuffle(1_000)
.batch(self.hparams.mixed_negative_batch_size)
)
train_with_mns = tf.data.Dataset.zip((train, uniform_negatives))
# Train.
self.model.fit(
train_with_mns,
epochs=self.hparams.epochs,
callbacks=[tensorboard_callback],
)Then mixed them in the compute_loss function.
Calculate the candidate and extra item embeddings and concatenate them together
Also concatenate the candidate_ids for correcting sampling bias and removing accidently hits
def compute_loss(self, inputs, training=False) -> tf.Tensor:
if training:
self.global_step.assign_add(1)
features, extra_items = inputs
user_embeddings = self.query_model(features, training)
candidates_embeddings = self.candidate_model(features, training)
negatives_embeddings = self.candidate_model(extra_items, training)
# we cannot turn on the topK metrics calculation for training when there is extra negatives, need modification on the Retrieval call function
# true_candidate_ids=candidate_ids[:tf.shape(query_embeddings)[0]])
candidate_ids = tf.concat(
[features[self.hparams.item_id_key], extra_items[self.hparams.item_id_key]], axis=-1
)
candidate_embeddings = tf.concat(
[candidates_embeddings, negatives_embeddings], axis=0
)
candidate_sampling_probability = self.sampling_bias(
self.global_step, candidate_ids
)Then that’s it. In my mini model on movielens 1M dataset, the extra nagatives don’t benefit the performance much. I think it’s because the corpus are too small. Still worth trying MNS on other dataset.
What’s next
In the next post, I will upgrade my sampling bias correction approach to support expiration function. So it can support an endless increasing corpus.
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/b9f4e78a8830fe5afcf2f0452862fb3c0d6584ea.pdf
https://medium.com/mti-technology/n-gram-language-model-b7c2fc322799
http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45530.pdf
Fan, thanks for sharing another great post. Really appreciate it if you can hep confirm my understanding of the effective sampling distribution Q for an item: (frequency in training) × (B/(B+B')) + (uniform frequency in index) × (B/(B+B')). For those items not in the training dataset, it becomes just (uniform frequency in index) × (B/(B+B')).