
Wide & Deep Learning for Recommender Systems
Revisiting the classic recommendation paper from Google

In this post, let’s revisit the W&D model from Google. This is one of the most important ranking models in the recommendation system history. Other famous models like DeepFM directly inherit the ideas from the W&D model.
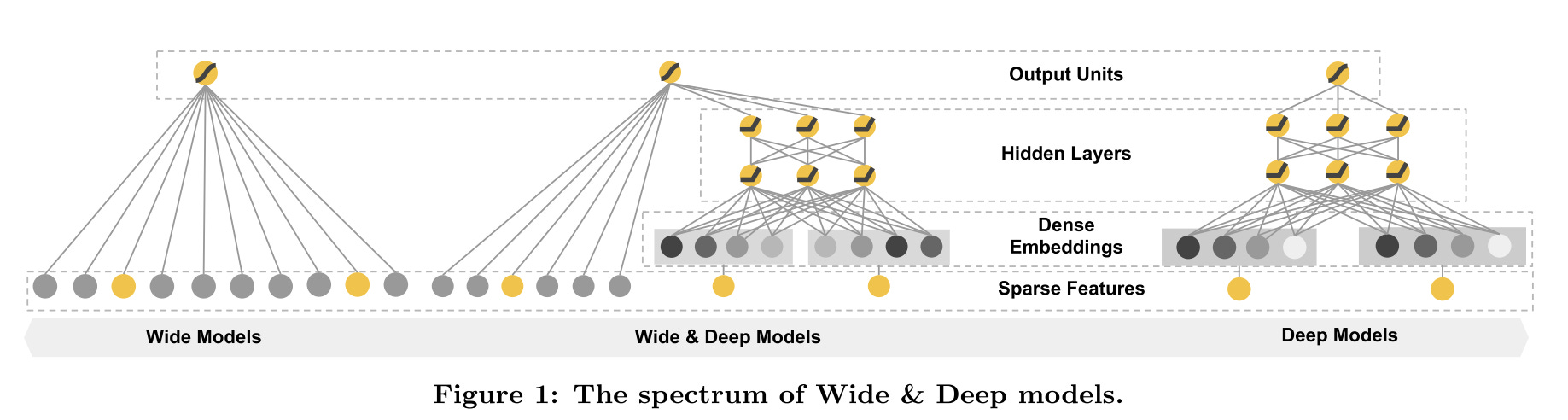
It consists of two parts, one is a linear model using cross-product feature transformations, and the other is a deep model using dense and sparse embedding features
LR (logistic regression) is the most popular model in the traditional industry ranking system. And as the popularity of deep learning rises, the idea of combing LR with a deep model naturally comes. That’s the original motivation of the W&D model
I will skip the basic introduction since most people are familiar with this model. Let’s focus on a few key questions.
QA
Generalization and Memorization
We are always saying that the deep part is for generalization and the linear part is for memorization. But how to understand generalization and memorization?
Generalization: what we have learned can be applied to unseen items or features. This is achieved by the embedding technique. By representing items into low-dimension embeddings, we can calculate the similarity or prediction score on seen or unseen items as long as we have embedding for them
Memorization: learn the frequent co-occurrence patterns in the input items or features and exploit the correlation with the target label. This is achieved by feature crossing, and the most common method is cross-product. Then one hot encoding will be used to transform the new feature to 1 or 0. For example, a cross feature AND(user_installed_app=netflix, impression_app=pandora”), whose value is 1 if the user installed Netflix and then is later shown Pandora
Can deep model memorize?
The hypothesis from the W&D paper brings us another question, the deep model does generalize well, but can the deep model also memorize patterns?
Actually, it can, but it’s less effective. We can see the result below (data from Machine Learning Design Patterns, feature cross chapter1). Deep learning requires much more training time and is cost-inefficient to achieve similar performance.
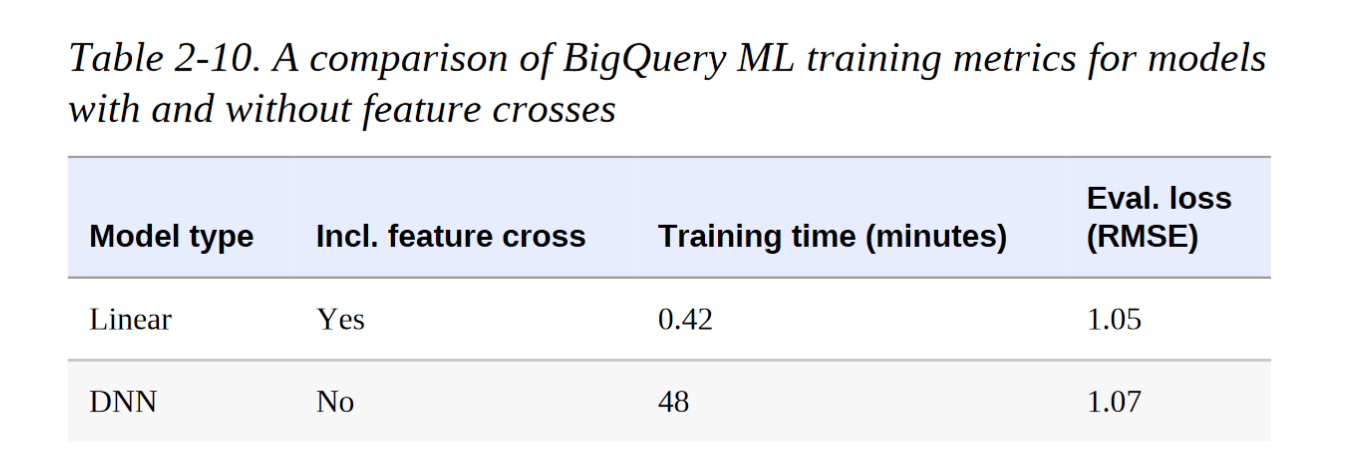
The deep model can also be thought of as a feature crossing layer to learn high-order feature interactions. So manually doing feature crossing benefits the naive deep model and helps it learns faster. That’s just a trade-off.
What features are used in the wide part?
As shown in the picture, many sparse and dense features are used in the deep part, which is also a common approach nowadays. But in the wide part, the only feature used is the cross-product of use installed App and impression App, i.e., the candidate.
The motivation behind this is there is a strong correlation between the installed App and the impression App. What the user has already installed is the core indicator of user preference. So it’s critical to do the feature crossing here manually.

How is the model trained?
The wide and deep parts are combined using a weighted sum and fed to a sigmoid function for joint training.
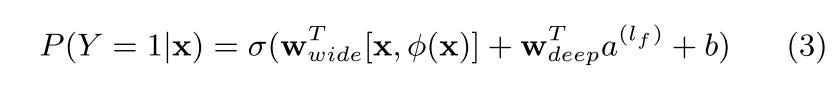
The wide part is optimized using the Follow-the-regularized-leader (FTRL) algorithm with L1 regularization
The deep part is optimized using AdaGrad
Why FTRL with L1 regularization?
The answer is all about sparsity. Considering the cross-product feature, installed App vs. impression App, in Google App Store, we have millions of Apps, and the cross-product can produce trillions of features if we only use a second-order cross. The number will be much higher if we try third or even higher-order cross.
The feature weights should be super sparse. Most cross features can’t be learned well with none or few training samples
The size of the wide part will be enormous, with trillions of feature weights
This is the reason for using FTRL.
How FTRL works?
This is a relatively complicated topic. Let’s try to be simple. For details, please refer to this paper written in Chinese.2
As we all know, the L1 regularizer can generate sparse weights for batch training. But L1 can’t bring good sparsity in the online training scenario, aka training samples one by one using SGD (Stochastic Gradient Descent). It’s hard to get sparsity because of the randomness of gradient descent directions

The core idea of achieving sparsity with L1 regularize is the Truncated Gradient, truncating the weight to zero when the value is smaller than a certain threshold

FTRL combines the advantage of the L1-FOBOS (Forward-Backward Splitting) algorithm, which has high accuracy but low sparsity, and the RDA (Regularized Dual Averaging) algorithm, which has low accuracy but high sparsity
FTRL has the best performance in the online learning scenario


How to finish online inference in 10ms?
The idea is simple, splitting the large batch into several small batches and running the request in parallel using multithreading.

Show me the code
TensorFlow now has a native API for the W&D model. I tweaked it a little bit to integrate it into the TensorFlow Recommender library.
Define the linear model for the wide part and the MLP model for the deep part

Create the training step and inherit it from the TensorFlow Recommender base model. Notice that here we have 2 optimizers, one is for the wide part, and the other is for the deep part.

For the wide part, define the input features. To follow the idea from the paper, I created several one-hot encodings of cross-product features from the MovieLens dataset. TensorFlow now also provides a HashCrossing layer, which is more convenient and we don’t have to build the vocabulary beforehand.

The last part is simply to compile the optimizer for the wide and deep parts. Here I’m using FTRL and Adam.

Train it! Just for a sanity check, we can further tune the performance if needed.

Weekly Digest
developer-roadmap, a community-driven roadmap, articles, and resources for developers

Choosing an open table format for your transactional data lake on AWS. A detailed comparison between popular lakehouse formats, including Apache Hudi, Apache Iceberg, and Delta Lake (In general, I would say Apache Hudi is the best)
PandasAI. Yeah, ChaptGPT in Pandas

A detailed comparison of REST and gRPC. The fundamental knowledge of these 2 most popular API styles
Helix, a post-modern text editor and a good replacement for Vim

https://www.oreilly.com/library/view/machine-learning-design/9781098115777/
https://github.com/wzhe06/Ad-papers/blob/master/Optimization%20Method/%E5%9C%A8%E7%BA%BF%E6%9C%80%E4%BC%98%E5%8C%96%E6%B1%82%E8%A7%A3(Online%20Optimization)-%E5%86%AF%E6%89%AC.pdf