
Dive into Twitter's recommendation system III - GraphJet
GraphJet: Real-Time Content Recommendations at Twitter (part II)

Let’s continue the discussion on GraphJet. In this post, we will look at the core components and design thinking of GraphJet. For the previous posts, please refer to


Overview
GraphJet maintains a bipartite graph that keeps track of user–tweet interactions over the most recent n hours.
Goals and Approach
MagicRecs proves the power of real-time recommendation. But MagicRecs can only be applied to limited tasks and users. Then the next question is how to build a scalable solution for a Graph storage engine. Here comes GraphJet.
The design philosophy is to do the minimum. My comment🤔: this makes sense, hah. Nobody wants to do extra work
The entire graph will fit in memory on a single machine. This is the most crucial assumption for the whole system. It’s based on two observations:
Twitter content evolves rapidly so does the graph
Users’ attention wanes with time
All the content can be kept within a time window, and old content will be expired. So the memory requirement won’t explode
Data Model and API
GraphJet manages a dynamic, sparse, and undirected bipartite graph:
Edge types are small and fixed, corresponding to the user actions like likes, retweets, etc
Memory requirements come from continuously inserting new user actions
Edges are stored as adjacency lists, implicitly conveying directionality. We can build either left to right or right to left index as we want
API is super simple, with only 5 in total:
insertEdge(u, t, r): inserts an edge from user u to the tweet of type r into the bipartite graphgetLeftVertexEdges(u): returns an iterator over the edges incident to u, a user on the left-hand sidegetLeftVertexRandomEdges(u, k): return k edges uniformly sampled with replacement from the edges incident to vertex u, a user on the left-hand sidegetRightVertexEdges(t): same as leftgetRightVertexRandomEdges(t, k): same as right
No delete API. How to control the memory?
Only keep the edges in recent N hours. Stale edges will be periodically pruned
Edge timestamp is not stored
This is also just a tradeoff between space and performance
The order is implicitly encoded in the monotonically increasing tweet ID
My comment🤔: this shouldn’t be an issue anymore, and we can leverage sequential algorithms to ingest the timestamp info
Offline experiments show that varying the size of the temporal window of the graph does have an impact on recommendation quality, but beyond knowing that interaction happened within the last n hours, we’ve found it hard to design algorithms that provide substantial gains by exploiting edge timestamps
Regarding consistency:
Calls to the get methods will return an iterator corresponding to a consistent graph state at call time. Newly arrived edges cannot be seen
No guarantee across calls. Multiple gets on the same vertex may indeed return different numbers of edges
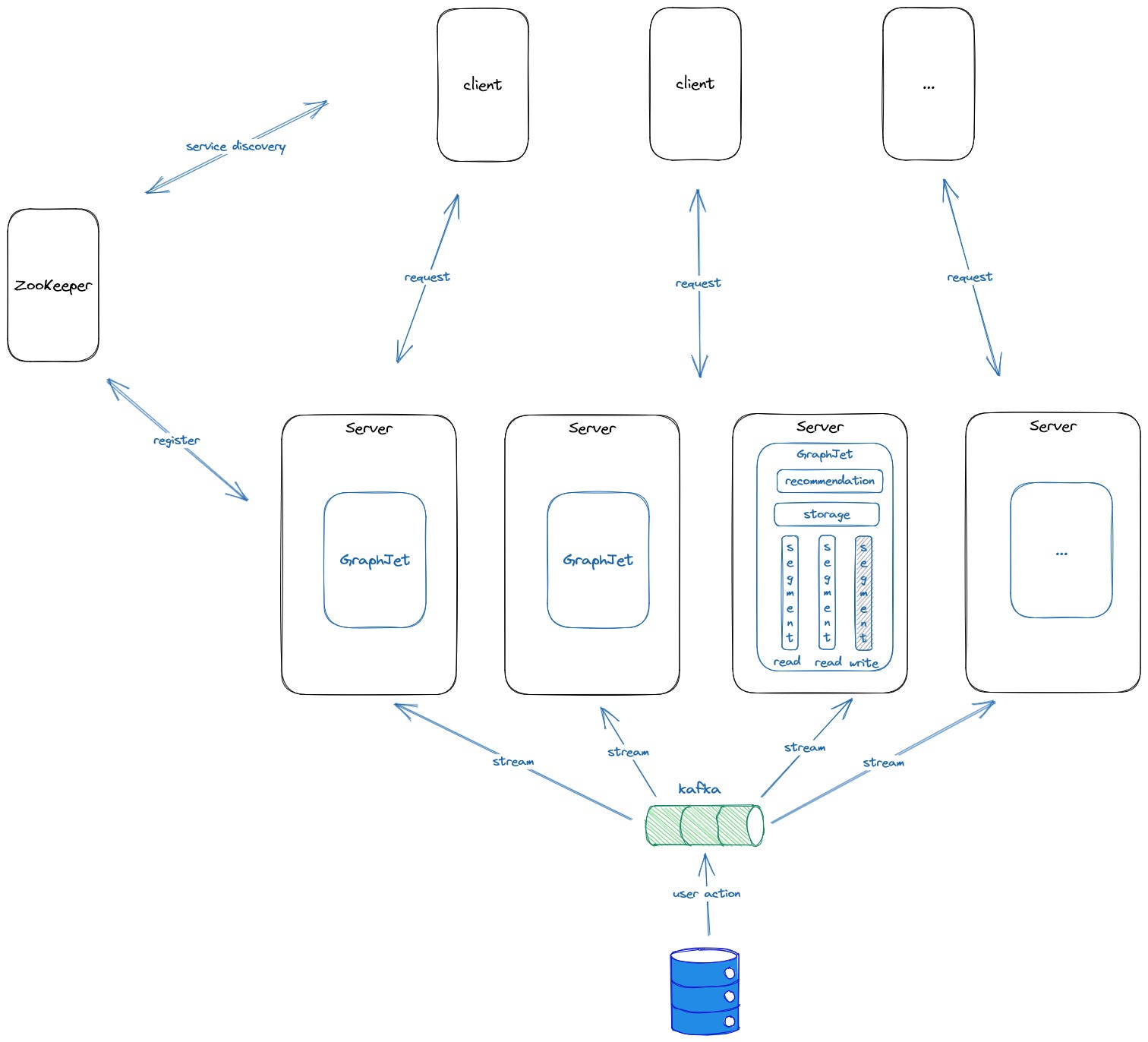
Overall Architecture

GraphJet is implemented in Java:
It maintains a list of temporally-ordered index segments comprised of adjacency lists that store a partition of the bipartite graph
The partitions are created periodically from scratch once the number of edges in the latest segment reaches a threshold
Read/Write patterns
Only the last segment can be written into
The remaining are read-only
Only one single write thread reading from Kafka. No need to consider race condition
Once one segment stops accepting new edges, it will be optimized for reading
Periodically, an entire segment will be removed if it’s older than N hours
Graph Operations
Edge Insertions
ID Mapping
The idea is straightforward, to reduce the memory requirements, they build an internal unique mapping between tweet ID and vertex id within one segment.
Hash the external vertex id and treat the hash value as the internal vertex id
Store the external vertex id in the hash table so that recovering those ids can
be accomplished by a simple array lookupFor convenience, the size of the hash table is a power of two so that mod can
be accomplished via efficient bit operations (👏 good trick)
The hash table is fixed since the mapping cannot be changed. How to handle rehash?
Have a reasonable estimation of hash table size based on historical data
Create another similar size hash table to record new vertices
Then the new ID = old hash table size + new hash table index
The edge type is bit-packed into the vertex ID, so the adjacency list is just an array of 32-bit integer
Insertion becomes simply adding a new integer element to the array
Memory Allocation
Ideally, the adjacency list should be maintained in a continuous memory region, but it can not be realized because of the randomness of edge insertions. Imagine user actions on tweets can happen at any time.
Twitter chooses to use discontiguous adjacency lists.
But how much memory should be allocated for a given vertex?
Their solution is to allocate memory for adjacency lists in slices that double in size each time we run out of space, i.e., the slice sizes grow as powers of two. My comment🤔: this is actually the standard approach for expanding the array
The adjacency list slices are organized by grouping all slices of the same size together in edge pools, which are implemented as large arrays. The first edge pool P1 is of length (2^1) · n, where n is the number of expected vertices in a particular segment. The r-th edge pool is denoted Pr and holds n/2^(r−1) slices of size 2^r
Illustrated in the picture, for example, v1 → 25 : P1(1), P2(2), P3(0), P4(0)
Edge pools containing slices for a particular size are allocated lazily—that is, the pools themselves are not created until they are necessary

Read-Only Optimizations
Reorganize the physical memory layout of the various data structures to support more efficient read operations.
Because we know the final degree of each vertex, we can lay out each adjacency list end to end in a large array without any gaps.
Edge Lookups and Sampling
How to implement read API?
getLeftVertexEdges:The returned iterator is a composition of iterators over edges in all index segments, from earliest to latest. Since in each segment, the edges are stored in insertion order, and the overall iteration order is also in insertion order.getLeftVertexRandomEdges:Sampling across index segments?The storage engine keeps track of vertex degrees across all segments
Normalize these degrees into a probability distribution from which we sample, where the probability of selecting an index segment is proportional to the number of edges in that segment
A probability table and an alias table for sampling are created at API call time, so no edges created after that time can be seen after
Real-time Recommendations
Two kinds of recommendations are supported:
Content recommendation queries: for a user, compute a list of tweets that
the user might be interested inSimilarity queries: for a given tweet, compute a list of related tweets
Full SALSA
Like the SALSA algorithm I discussed in the last post, the recommendations are generated by running a personalized SALSA on the graph.
Begin with the vertex in the bipartite interaction graph that corresponds to the
query user and run SALSAFrom query u, uniformly select one of its edges to visit tweet t
From t, run the same process back to the left side
Repeats an odd number of steps
Summarize the visit distribution
To introduce personalization, they introduce a reset step on the left-to-right edge traversals: with a fixed probability α, we restart from the query vertex to ensure that the random walk doesn’t “stray” too far from the query vertex
Cold start: Start the random walk from a seed set instead of a single user vertex. The seed set is configurable, but a common choice is the user's circle of trust
Subgraph SALSA
To generate a good recommendation reason, Twitter calls this “social proof”. They further introduce another variant of SALSA - by restricting the output set to only neighbors (on the right-hand side) of the seed set.
Different from Full SALSA, the algorithm starts from a seed set
Assign a uniform weight for each vertex in the seed set that sums to one
For each tweet on the right side, sums the weights received from the left
And apply the same process back to the left side
Similarity
How to realize similarity queries:
Calculate the cosine similarity of the neighbors of tweet t
Where N (t) denotes the left-side neighbors of vertex t
Then construct a ranked list of tweets with respect to the similarity metric.
Run another round of random walk
For a vertex t, sample its neighbors N(t) according to the weights which are proportional to the similarity metric
Then do the same thing from left to right

Deployment and Performance
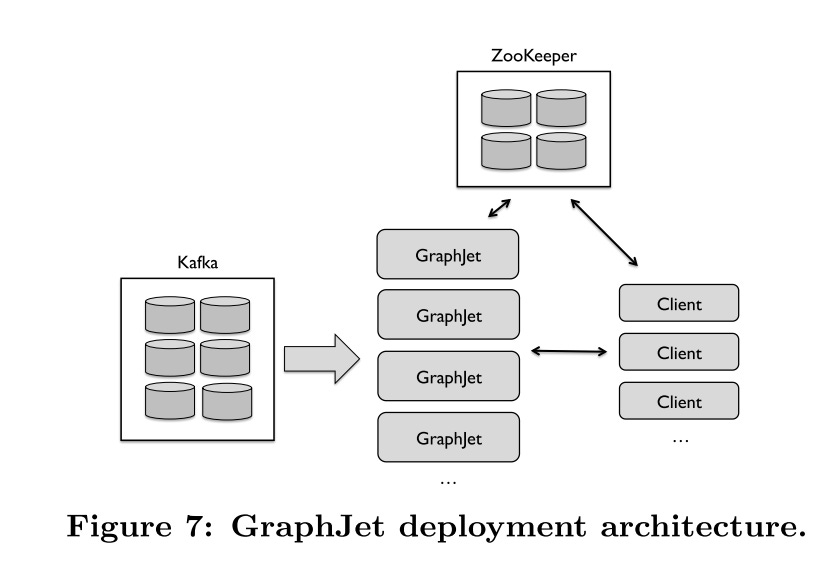
As illustrated in Figure 7:
Each individual server holds a complete copy of the interaction graph, fault tolerance is handled by replication
In a steady state, the bipartite interaction graph stored in each GraphJet instance can hold O(10^9) edges using less than 30 GB of RAM (This is roughly 32-bit for each edge, as we discussed above)
At the beginning of 2016, the entire service receives tens of thousands of recommendation requests per second, with results reaching many millions of users each day
GraphJet can sustain one million edge insertions per second reading from the Kafka queue to “catch up” to the current state of the graph
An individual GraphJet server can support up to 500 recommendation requests per second, with a latency profile of p50 = 19ms, p90 = 27ms, and p99 = 33ms at that load (So roughly 20 servers are running to support all the requests)
The success rate of the system in delivering recommendations, as measured from the clients, is consistently above 99.99% in terms of requests across all users
The last time worth mentioning is the general architecture of GraphJet borrows heavily from Earlybird, Twitter’s production real-time search engine. My comment🤔: yeah, nothing comes from nowhere
Weekly Digest
Artist Transforms Fluffy Clouds Into Playful Cartoon Characters Every Day

Will we run out of ML data? Evidence from projecting dataset size trends
Our projections predict that we will have exhausted the stock of low-quality language data by 2030 to 2050, high-quality language data before 2026, and vision data by 2030 to 2060. This might slow down ML progress.
Scaling deep retrieval with TensorFlow Recommenders and Vertex AI Matching Engine. Vertex AI now supports ANN natively. This is an official example
DoorDash identifies Five big areas for using Generative AI. The problem is how good AI is. I don’t think Generative AI can beat the recommendation models now
Assistance of customers to complete tasks
Better tailored and interactive discovery
Generation of personalized content and merchandising
Extraction of structured information
Enhancement of employee productivity
From PostgreSQL to Snowflake: A data migration story. Reasonable but not fancy.

What’s Next
Let’s go to the most important and advanced candidate retriever in Twitter.
SimClusters: Community-Based Representations for Heterogeneous Recommendations at Twitter1

https://dl.acm.org/doi/pdf/10.1145/3394486.3403370