
Dive into Twitter's recommendation system II - GraphJet
GraphJet: Real-Time Content Recommendations at Twitter (Part I)

This is the second post on Twitter’s recommendation system. For the first post, please refer to

In this post, let’s look into the details of GraphJet1:
It’s quite a long paper covering infrastructure engineering and recommendation algorithm topics. There are many highlights worthing discussion on both sides.
Compared to RealGraph, GraphJet’s main duty is to generate relevant content for users, and it also supports generating similar items for both users and tweets
In short, GraphJet is an in-memory graph processing engine that maintains
a real-time bipartite interaction graph between users and tweets. Here in-memory and real-time are the keywords. They are the hard design constraints for the whole system
This paper traces the evolution of graph recommendations at Twitter over four generations of systems: Cassovary, RealGraph, MagicRecs, and GraphJet. This gives us an excellent example of how the system evolves in a real production system
It currently serves about 15% of Home Timeline tweets, considering only 50% of tweets come from the out-of-network source. So it actually serves 30% of the out-of-network tweets. The remaining 70% comes from the Embedding Spaces
System evolution
WTF and Cassovary
Overall architecture
Below is the architecture of WTF and Cassovary. This is the beginning version of the graph system back in 2010.
Quick launching is the top priority. So in this design, they assume the entire graph can be fit into memory on a single server. And it works well
In the picture, Cassovary, the in-memory graph processing engine is the core.
FlockDB is the front-end graph store, which stores the metadata and user behavior information in the production
A follower graph snapshot is dumped daily from FlockDB into HDFS
Cassovary loads the graph data from HDFS and builds the in-memory graph
Cassovary provides vertex-based queries and recommendation API to compute the WTF suggestions
Cassovary constantly consumes user action messages from a distributed queue (not included in the picture). Then the result is written to a MySQL DB called WTF DB
The WTB DB serves online queries from Web and App old users
Cassovary can be simply horizontally scaled by adding new instances because of the in-memory design
For new users - the cold start problem is addressed by a completely different path, the left branch in the picture. Here they didn’t share the details. Probably some rule-based heuristic recommendations

Recommendation algorithms
As listed below, there are two robust algorithms in this system that GraphJet also inherits:
Circle of Trust, representing the most relevant users, results from personalized PageRank (details will be shared later)
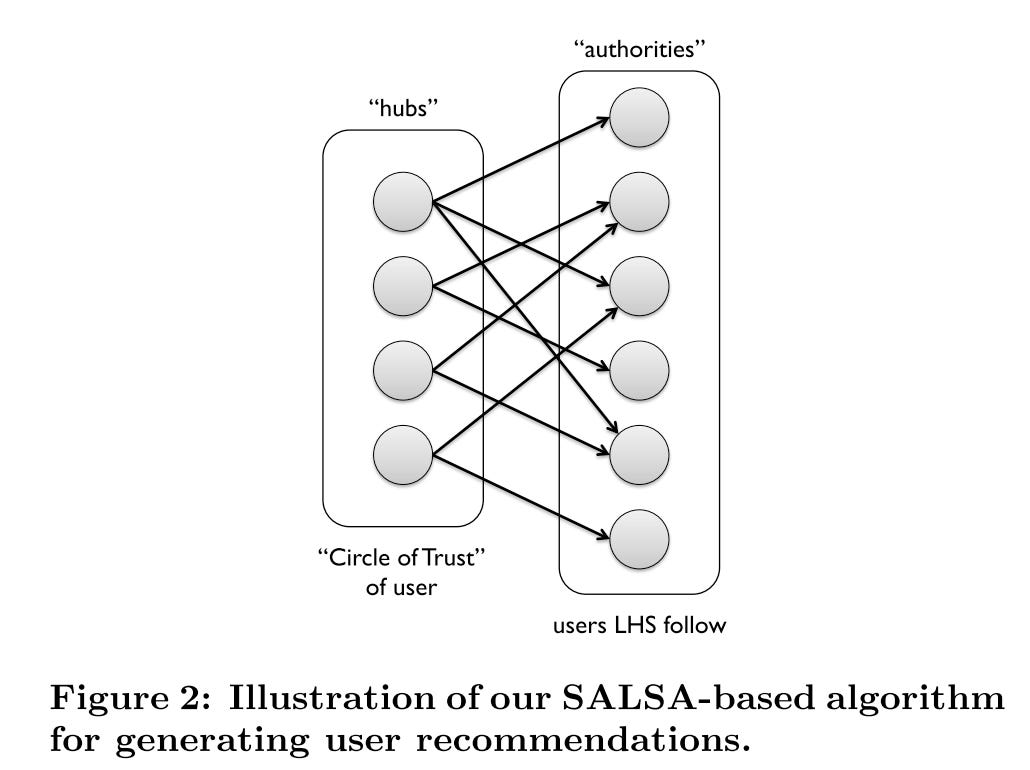
SALSA - Stochastic Approach for Link-Structure Analysis
Like HITS, it’s a random walk algorithm that splits nodes into hubs(left) and authorities(right) 2
hubs represent vertices that have large outdegrees, correspond to users
authorities represent vertices that have large indegrees and correspond to tweets that the users act on
After multiple rounds of SALSA iteration, we assign scores to the left and right vertices. The left vertices will be the similar users, and the right vertices will be the relevant tweets
Hadoop and RealGraph
This is the second version of the recommendation system:
Cassovary only leverage follow signals. Twitter has a strong desire to exploit broader signals
They focus on how to scale the system to ingest more signals, and by that time, they haven’t realized the importance of real-time recommendation. So the design is still focused on offline batch solutions
The Design decision, build the system on Hadoop
Twitter has a well-maintained Hadoop platform using Pig
MapReduce is not good at handling graph data, but no other better production-ready platform
They define a UDF to encapsulate the algorithms, but this brings the data shuffling issue - collecting the neighborhoods across the cluster nodes
This issue is tackled by a sampling technique (No detail mentioned in the paper)
This solution becomes the RealGraph
As we shared in the last post, it incorporates various signals and generates candidates
And its data is also used to train the ranking model
My comment🤔: This structure becomes the prototype of Twitter’s recommendation system

MagicRecs
Nearly all recommendations from Cassovary and RealGraph are generated in batch on a daily basis. But on Twitter, they observe that real-time recommendations based on recent signals tend to be more engaging. This really makes sense. Tons of people on Twitter are chasing the latest news.
How to verify the hypotheses?
Here Twitter uses a smart solution. They create an account called MagicRecs:
It sends real-time recommendations to the followers via direct messages
They implement a brute-force algorithm that isn’t scalable. But for this account, this is enough to be a proof of concept
How does MagicRecs work? It’s actually straightforward:
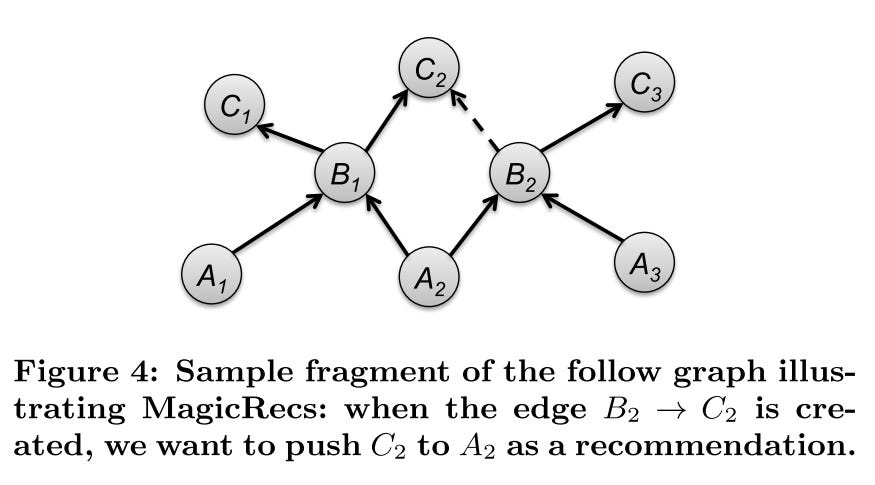
Suppose we want to build recommendations for a group of users A
In the picture, we see A2 are following B1 and B2
If B1 and B2 follow the same user C2, this means C2 is a hot user (here, the following threshold is set to 2)
Then use push to recommend C2 to A2
The same logic applies to other content recommendations
The result achieves high engagement 🚀
In this manner, this problem is reframed to
given the addition of a particular edge e from u to v, what recommendations can we make to whom? The recommendations usually do not directly involve either u or v, but rather their respective local neighborhoods.
This problem turns into a real-time recommendation problem on streaming graphs. This is a relatively new area, and they have to build it from scratch:
Smart as usual, they reformulate the problem as an intersection of adjacency lists
Store the outgoing edges of A and the incoming edges of C
Then intersect the edges at B, finds all Bs that have a higher cardinality than the threshold
The final system is built in a local mode again, and all the calculations are done locally, so there is no need for cross-node traffic
The calculations only take a few milliseconds
Let’s stop here for now. We can see clearly see how the ideas evolve within Twitter 🎯:
Prototype first, use simple but effective methods to verify the ideas
Keep iteration, step by step, each time introducing a new requirement to the system
Steady pace, Twitter doesn’t take aggressive techniques from outside. They tend to reuse their infrastructure and build things from scratch
Simplicity, they can always simplify problems and use basic methods to solve complex issue. This is impressive💡
Weekly Digest
Kindergarten children dropped seeds in the crack of the sidewalk to see what would happen. Nature is everything

How I Research A New Subject. When you’re doing serious research, you’ll never truly retain information unless you’re writing it down
TLDR: The Multi-Million Dollar Newsletter Run by 1 Guy. How to grow your audience? Paid ads don’t make your business any less of a business
AWS guides, The Open Guide to Amazon Web Services
Why we're leaving the cloud. Renting computers is (mostly) a bad deal for medium-sized companies like ours with stable growth

What’s next
In the next post, let’s go to the core of GraphJet, its subtle and brilliant design

https://www.vldb.org/pvldb/vol9/p1281-sharma.pdf
https://www.ccs.neu.edu/home/vip/teach/IRcourse/4_webgraph/notes/najork05_HITS_vs_salsa.pdf