
FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction
The SOTA of CTR prediction model from Huawei

Today, let’s read a short paper from Huawei Noah’s Ark Lab1. This is a new model published on May 2023 and achieved the best performance in the Criteo CTR prediction task.
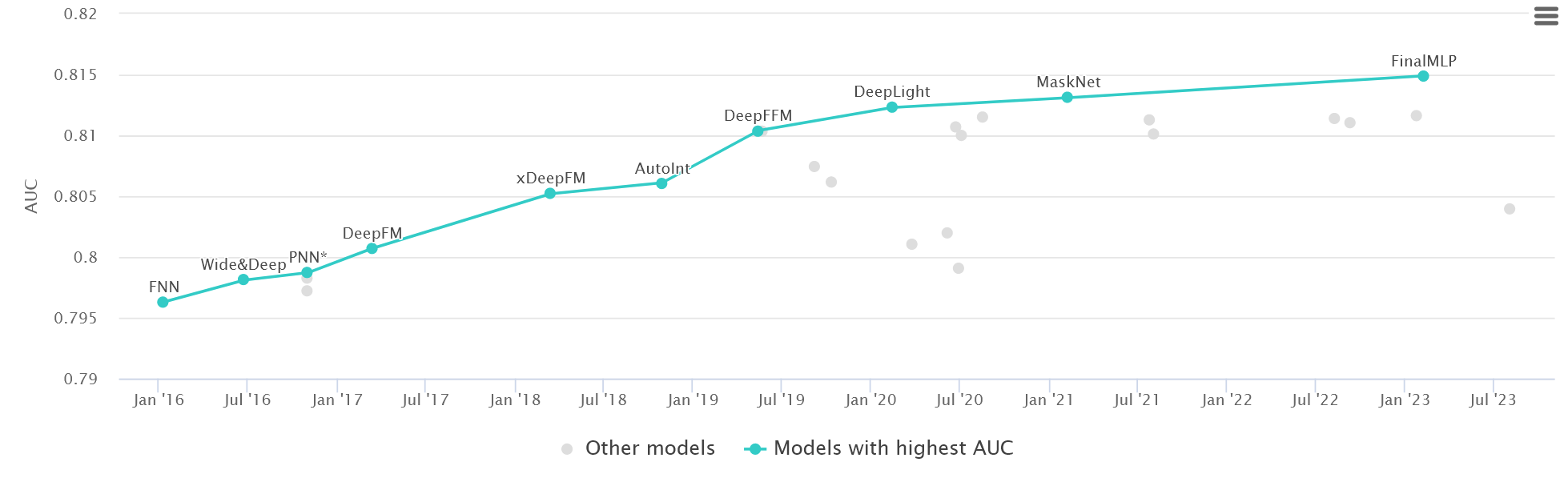
The idea behind this paper is a bit surprising:
Traditional ranking models usually count on the Wide and Deep structure. The wide part is composed of one or multiple stacked linear/Cross Network/FM layers and the deep part is an MLP layer
Many papers argue that the MLP is inefficient in catching feature interactions, especially multiplicative relationships
But in the FinalMLP paper, the two-stream MLP structure replaces the wide part with another MLP layer that can achieve surprisingly good performance. They call it a DualMLP model
They further introduce pluggable feature gating and interaction aggregation layers to enhance the DualMLP model and it is called FinalMLP
Note that in the DCN V2 paper, the author also shares a similar idea that a well-tuned MLP layer is a very strong baseline.
Paper Reading
The Overall Architecture
From bottom to top, there are 4 major components in FinalMLP:
The first part is a common embedding layer to transform inputs
The second part is a Feature Selection or Gating layer. Inspired by the gating mechanism from the MMOE model, they perform feature gating from different views via conditioning on learnable parameters, user features, or item features, which produces global, user-specific, or item-specific feature importance weights respectively
The third part is a two-stream feature interaction layer, which consists of two parallel MLP layer
The last part is a bilinear fusion layer, which creates a 2d weight matrix to learn the feature crossing between the outputs of the two-stream MLP layers. They further borrow the idea from multi-head attention and split the weight matrix into several small chunks. This approach can reduce the training cost and perform much better than naive concatenation.
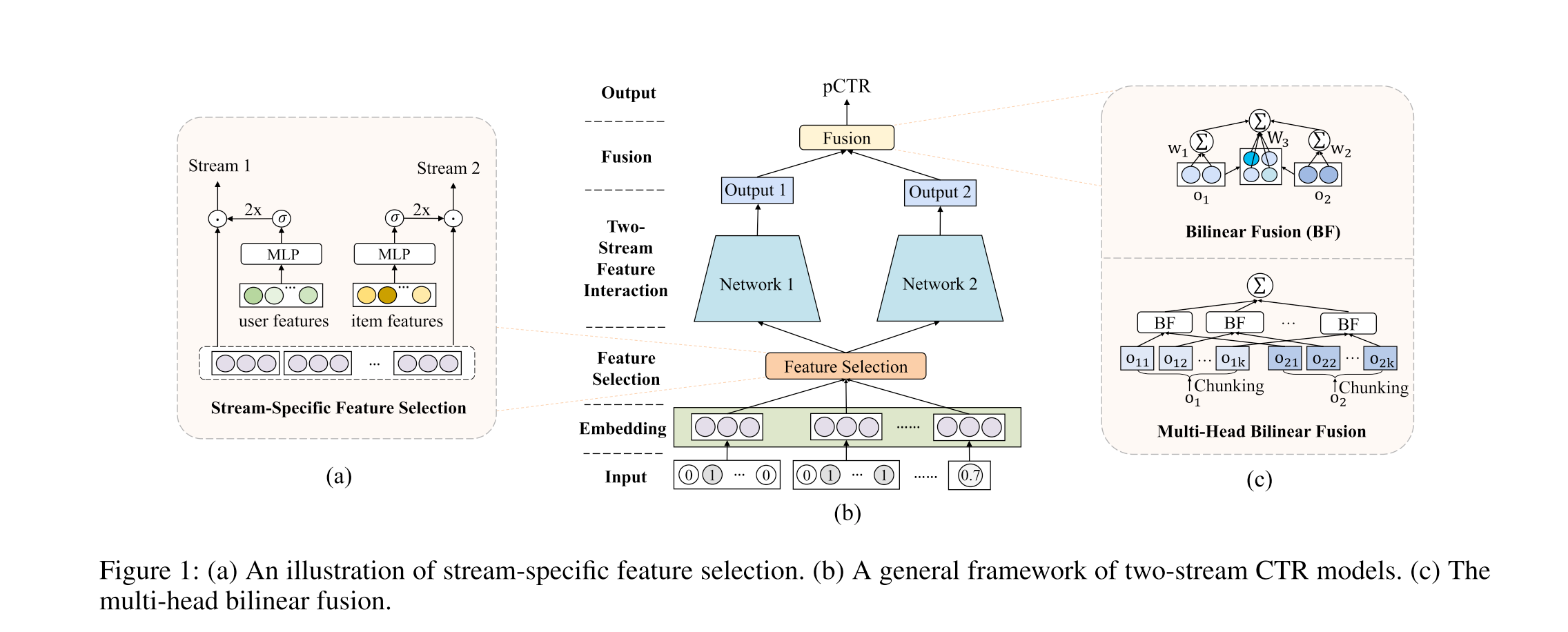
Let’s dive deep into the feature selection and fusion layer.
Feature Selection
Recall the InstanceGuidedMask layer from MaskNet, I would say the idea behind the feature selection layer is similar. They both leverage other features to select and mask the input features. But here the input of the gating network is flexible, and it can be a subset of either global, user, or item features.

The gating layer is defined as follows:
Gate_i denotes an MLP-based gating network, that takes stream-specific conditional features x_i as input and outputs element-wise gating weights g_i
Here x_i can be either a set of user, item features, or learnable parameters
Then a sigmoid function σ and a multiplier of 2 are applied to the gating weights to transform the output to a range of [0, 2] with an average of 1
e is the original input feature embedding, the final output h_i is obtained by an element-wise product between e and gating weights
The feature selection layer allows us to make differentiated feature input for the following two-stream MLP layers. This reduces the homogeneous learning between two similar MLP streams.
Bilinear Fusion
As I mentioned above, existing papers mostly use concatenation as the fusion layer, but it cannot catch stream-level feature interactions. So in this paper, they propose a bilinear interaction aggregation layer to fuse the output of two streams. A basic version is:
Here b is the bias. w_i is the linear weight for o_i. And the W_3 models the second-order interaction between o_1 and o_2.
Note that when the dimension of o_i is high, the W_3 matrix can be huge. So inspired by the multi-head attention, they further introduce a multi-head bilinear fusion that chunks the W_3 matrix into several small sub-matrices.
Here k is a tunable hyperparameter and o_ij denotes the j-th subspace representation of i-th output vector. Then the final output is aggregated by sum pooling.
Here the BF is the bilinear function above. The computation complexity is reduced by the number of k to O(d_1*d_2/k).
Experiments
Highlights:
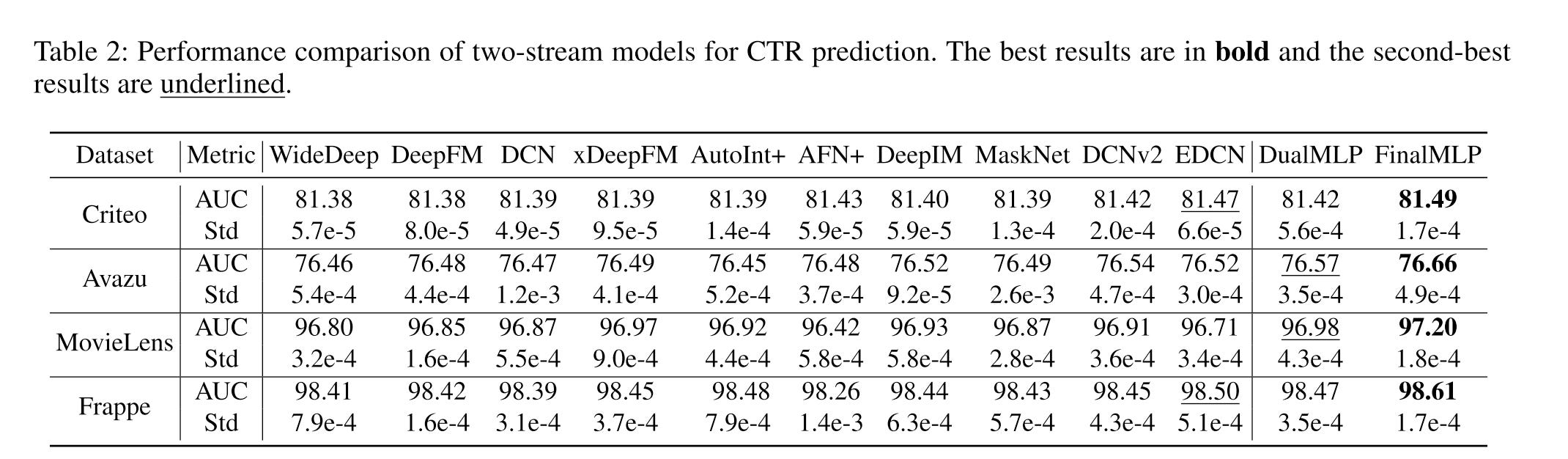
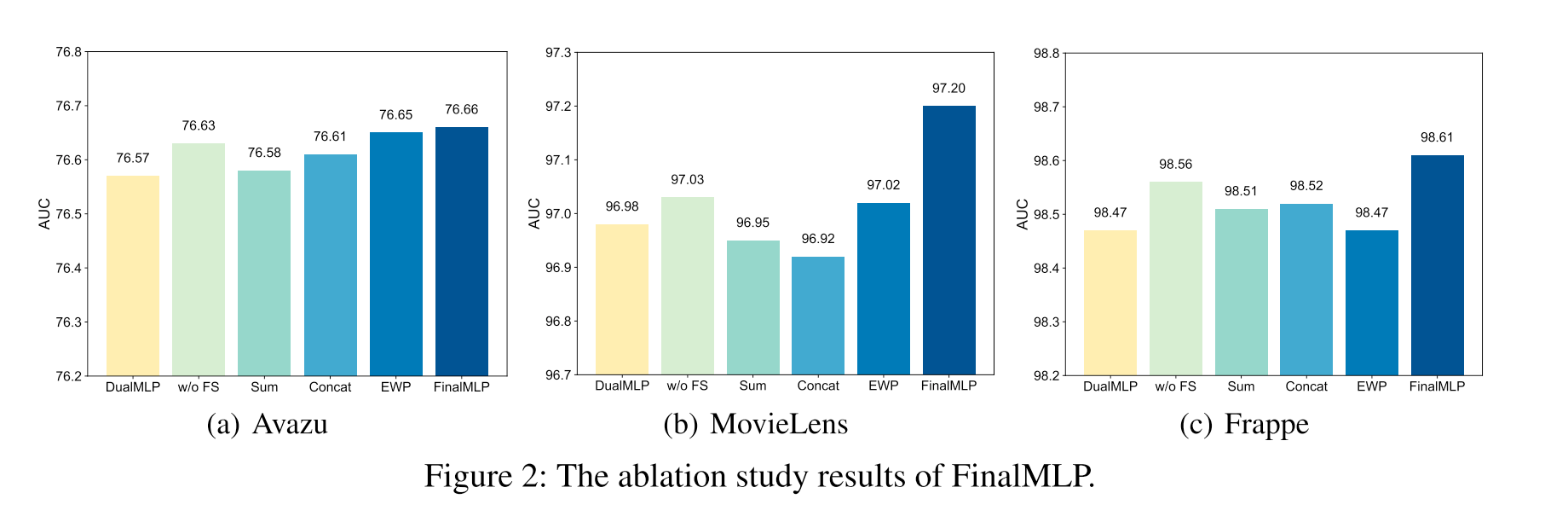
DualMLP is quite strong, in most cases it’s the second best.
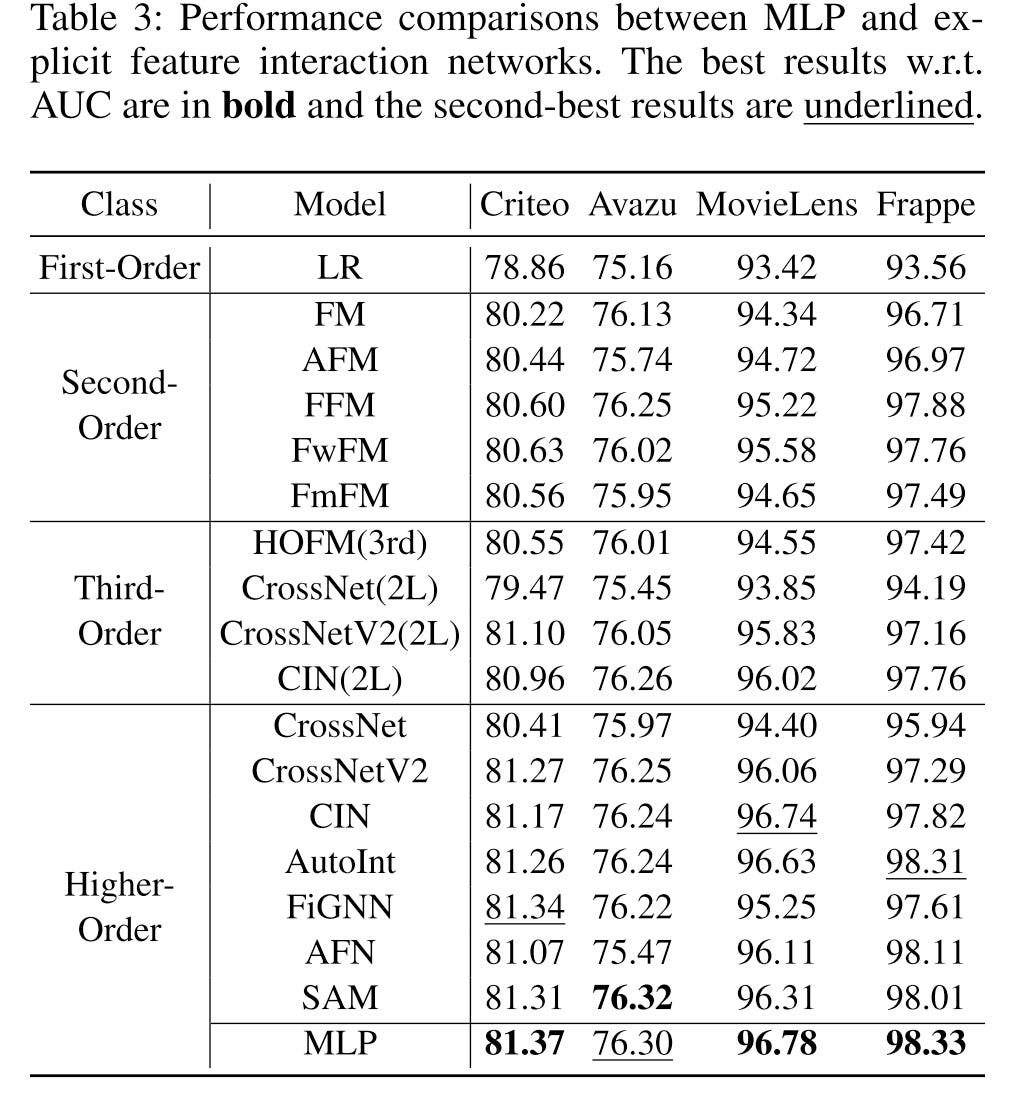
MLP is stronger than most explicit feature interaction networks. This conclusion is opposite to the result in the DCN V2 paper. I doubt this could be caused by extensive tuning.
In the ablation study, they observe that bilinear fusion plays a more important role than feature selection since replacing the former causes more performance degradation.
My thoughts
Although there is no formal proof in the paper that shows the strength of the feature selection layer. FinalMLP opens up a new way to make feature selection/masking controllable.
For instance, user behavior sequence features are very important in most cases. We can certainly use it as the input for one-stream feature gating. For the other stream, we can also consider using rich word or image features for feature gating.
Regarding the fusion layer, it can be considered an explicit feature interaction operation. We can also try other interaction networks like Cross Network.
Code Sharing
DualMLP
This network is simple, just concatenates two MLP layers.

FinalMLP
The original code is written in PyTorch. Here I provide a TensorFlow 2 version. Apply two feature selection operations and apply interaction layers on the output.

Feature Selection Layer
This part is simple, just create two dense layers to extract the gating weights.

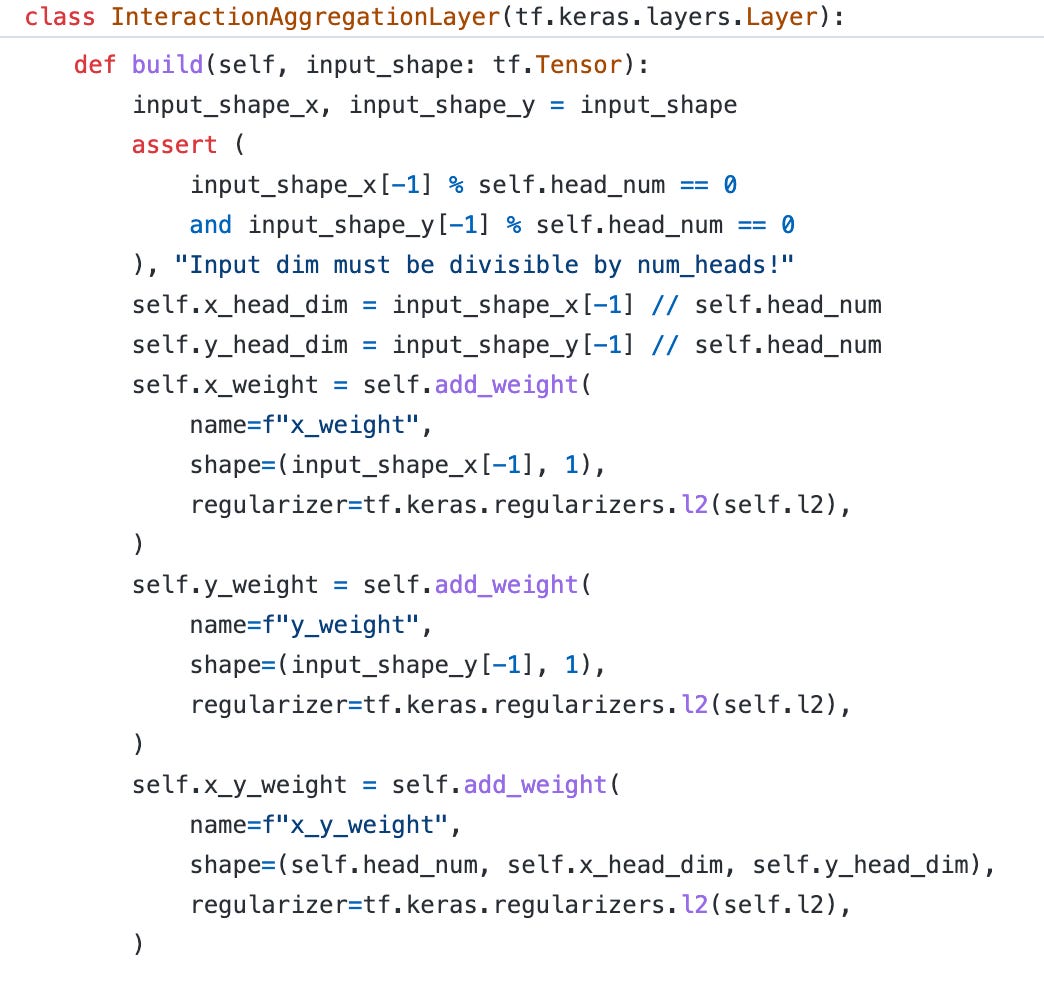
Fusion Layer
First, we need to define the three weight matrices. Notice that the input dimension must be divisible by the head number.
Then calculate the logits for o_1 and o_2 separately (here are x and y). Then apply the chunk-wise matrix multiplication. Notice that every small chunk o_1j is only multiplied by their corresponding pair o_2j. There is no cross-multiplication.

That’s all for this paper. 🎯
Weekly Digest
How to Learn Better in the Digital Age. Learning is what turns information consumption into long-lasting knowledge. The two things are different: while information is ephemeral, true knowledge is foundational. If knowledge were a person, information would be its picture
A side-by-side comparison of Apache Spark and Apache Flink for common streaming use cases
Most tech content is bullshit. This pattern is consuming — instead of creating. Consuming — without questioning. Consuming and hiding behind an authority
The past is not true. You can change your history. The actual factual events are such a small part of it. Everything else is perspective, open for re-interpretation. The past is never done
https://arxiv.org/pdf/2304.00902.pdf