
Dive into Twitter's recommendation system V - MaskNet
Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask

In this post, let’s look at the main ranking model for Twitter’s recommendation system - MaskNet1. For the previous posts, please refer to




It came from Sina Weibo in 2021. At first, it was a bit shocking to me that Twitter borrows ideas from a Chinese company. But it does make sense because of the similarity of product and scale of these two companies
This is an industrial paper, which means it’s practical and easy to read. There are no complex math or algorithms. Take a breath and relax :)
It focuses on one core problem of the ranking model, aka, effectively modeling high-order feature interactions. And its main contribution is a module called instance-guided mask which performs element-wise product both on the feature embedding and feed-forward layers guided by input instance. And it can be regarded as a special kind of bit-wise attention
It further combines the instance-guided mask with LayerNorm and feed-forward layer into a new module called MaskBlock, then proves it can be an effective building block for ranking model
Finally, the MaskNet consists of MaskBlocks, and it has two modes, parallel and serial
The overall structure of MaskBlock is listed below:

Paper reading
Introduction
Feature interaction is critical for CTR tasks, and it’s important for the ranking model to capture these complex features effectively:
Additive feature interaction, particular feed-forward neural networks, is inefficient in capturing feature crosses. My comment🤔: capturing high-order feature interaction requires tremendous training data and model capacity. That’s why so many models, like DCN, DeepFM are trying to model feature interactions explicitly
Here comes the instance-guided mask, which utilizes the global information collected from the input instance to dynamically highlight the informative elements in feature embedding and hidden layer in a unified manner:
The element-wise product brings multiplicative operations
The bit-wise attention guided by input-instance can both weaken noisy features and highlight informative features
The contributions:
Instance-guided mask = feature embedding + feed-forward layers. My comment🤔: this is the most innovative part 👏
MaskBlock = Instance-guided mask + LayerNorm + feed-forward layer. My comment🤔: this is a simple combination of standard modules
MaskNet = multiple MaskBlocks + stack/concatenation. My comment🤔: this shares the same idea with DCN V22
Real-world experiments prove that MaskNet outperforms. My comment🤔: this is what every experiment should do. I also have concerns about the result, details shared in the last section
Proposed Model
We are already familiar with fundamental conceptions like embedding, mask, and normalization. Let’s focus on the core model part.
Embedding Layer
The only thing worth mentioning is the basic conception. What is an instance?
Here the so-called "instance" means the feature embedding layer of the current input instance
Instance-Guided Mask
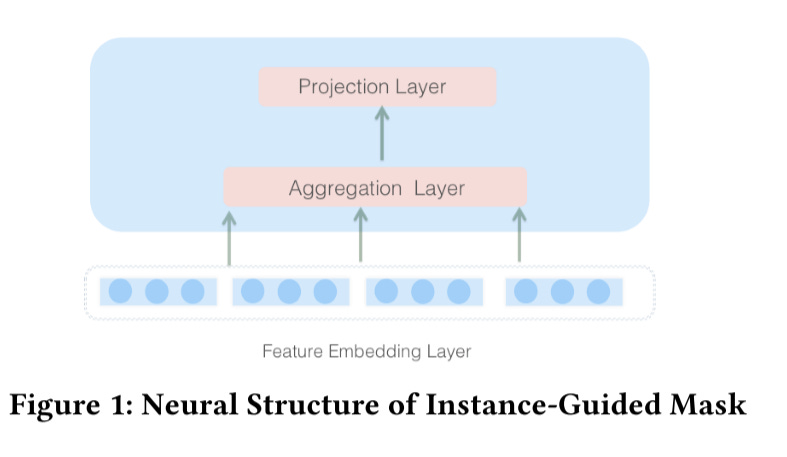
The instance-guided mask consists of three parts:
Input feature embedding layer
Aggregation layer, a wider layer compared to the projection layer, collects global contextual information in the input layer
Projection layer, reduces the dimension to the same size as the input layer (could be either feature embedding or other hidden layer output)
To perform element-wise product, there is an implicit requirement that the output dimension (the projection layer dimension) of the instance-guided mask should be equal to the dimension of the input layer.
So a reduction ratio is defined to control the ratio of the number of neurons in the aggregation and projection layers.
MaskBlock
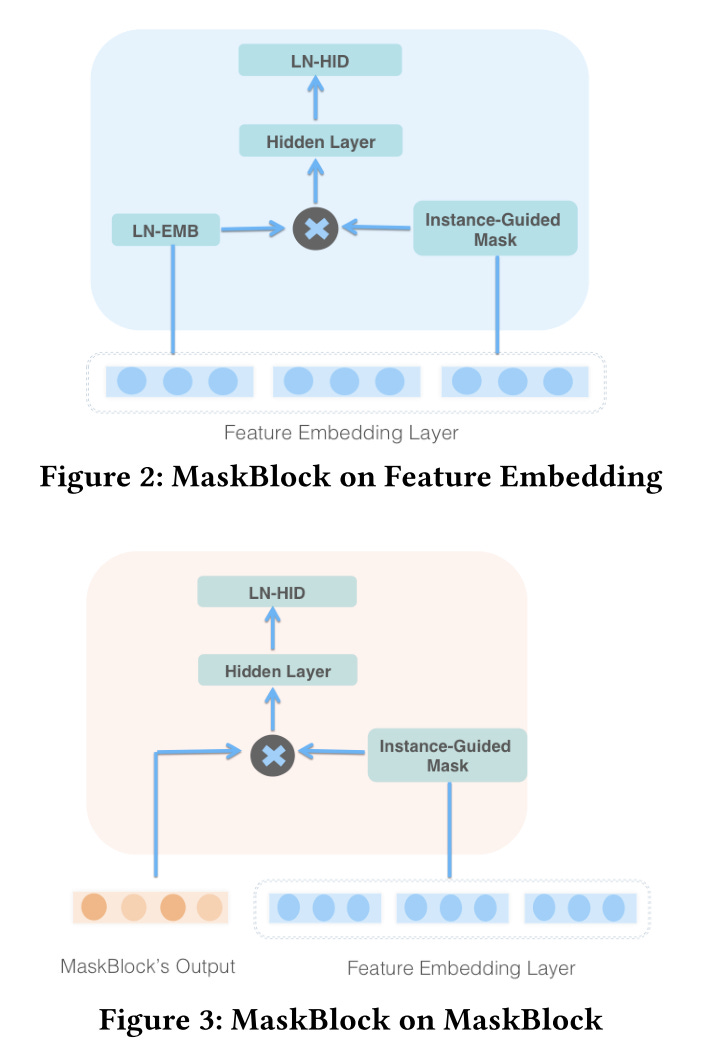
The MaskBlock consists of:
Layer normed input feature embedding
Instance-guided layer, element-wise multiply the input feature embedding
A variant of feed-forward layer, dense layer + layer norm + Relu activation
We can see from the picture there are two forms of MaskBlocks
For the first form, MaskBlock on feature embedding, the input is only the feature embedding:

For the second form, MaskBlock on MaskBlock, the input is the output of the previous MaskBlock, and the feature embedding.

MaskNet
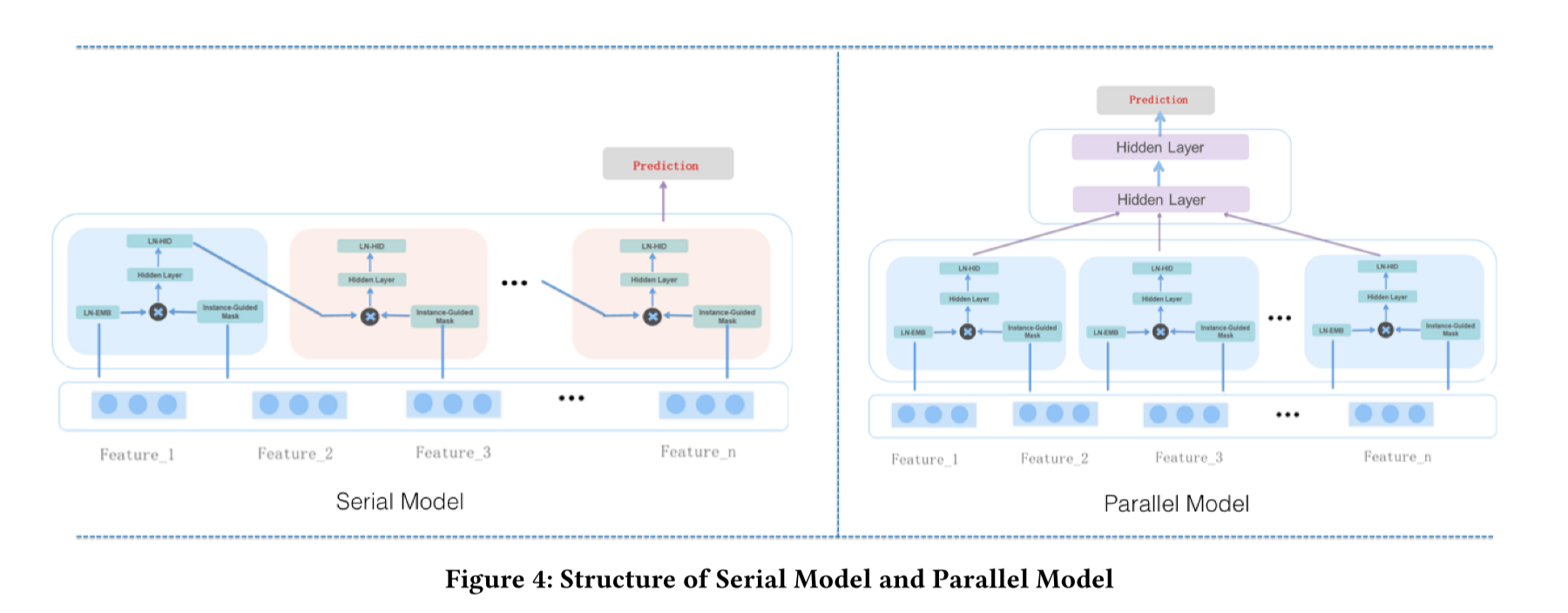
There are two ways of constructing MaskNet from MaskBlocks:
Stack, or the serial model, the input of the current MaskBlock is the output of the previous MaskBlock, and the final output is fed to the prediction layer
Parallel, concatenate the output of multiple MaskBlocks together and feed it to several feed-forward networks. Then finally, the prediction layer
The prediction layer is a sigmoid function to transform the input into a binary. The loss is defined as log-loss.
Experimental Results
Experiment Setup
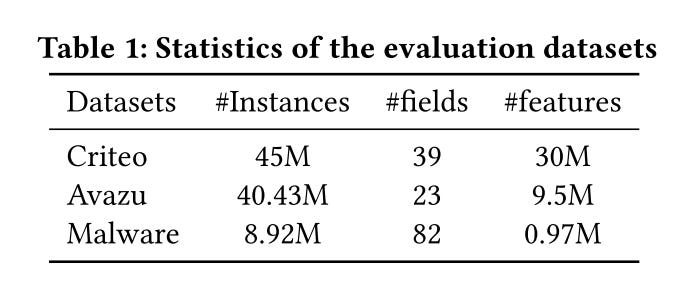
Three popular datasets for CTR prediction
Evaluation metrics: AUC and RelaImp (relative improvement). RelaImp is a normalized metric on AUC.

Parameter settings:
Adam + 0.0001 LR + batch_size 1024
Field embedding dimension set to 10
For the DNN part of models, the depth is 3, and the number of neurons per layer is 400
The reduction ratio is set to 2
Performance Comparison

We can see that on all datasets, the MaskNet outperforms a lot:
the baseline FM by 3.12% to 11.40%, baseline DeepFM by 1.55% to 5.23%, as well as xDeepFM baseline by 1.27% to 4.46%
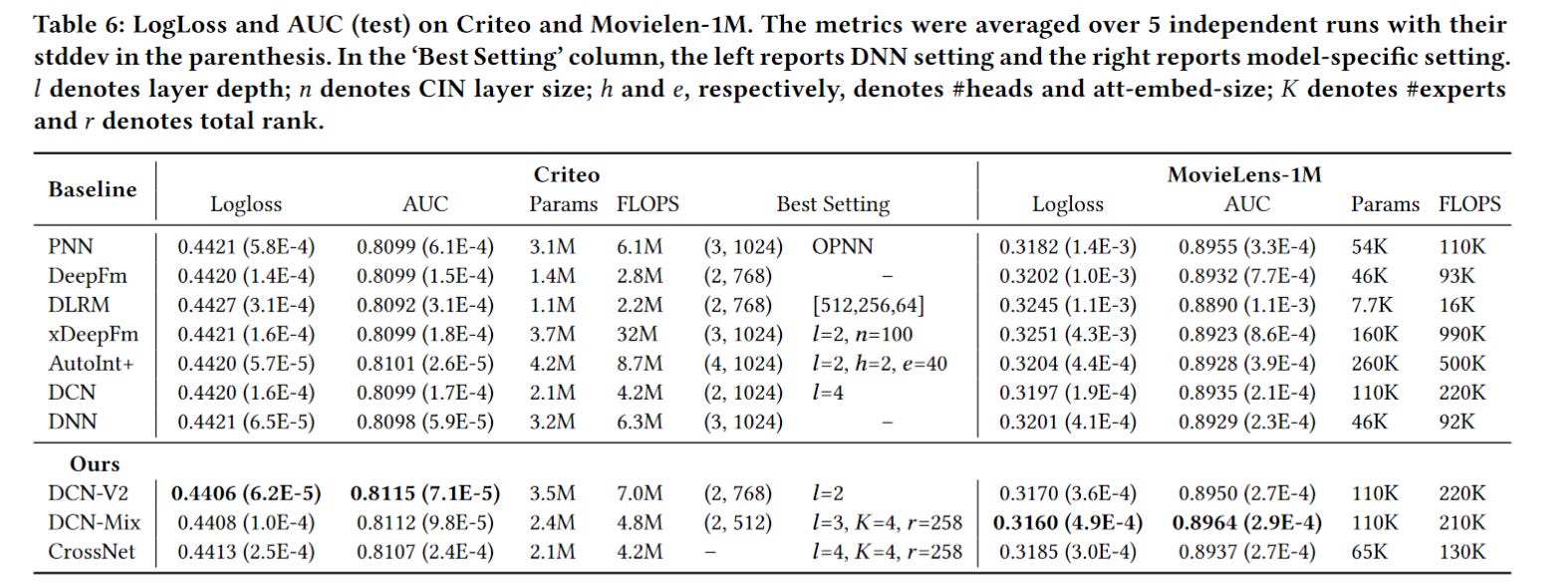
But if we look at the result from the DCN V2 paper on the same datasets, like Criteo. The results are different:
DCN and DCN-V2 outperform XDeepFM, which is opposite to the result in MaskNet. And the absolute value of AUC differs by 0.0041 for DCN, 0.0040 for DeepFM, and 0.0042 for XDeepFM.
On average, there is a 0.004 difference between these two papers. And the improvement from MaskNet compared to DCN is around 0.0066. This means the improvement could be much smaller if MaskNet authors carefully tune the DCN or DeepFM models
Why is there a huge gap? My comment🤔: tuning other baselines is pretty trivial and time-consuming. And a strong baseline cannot benefit experimental results, right!?
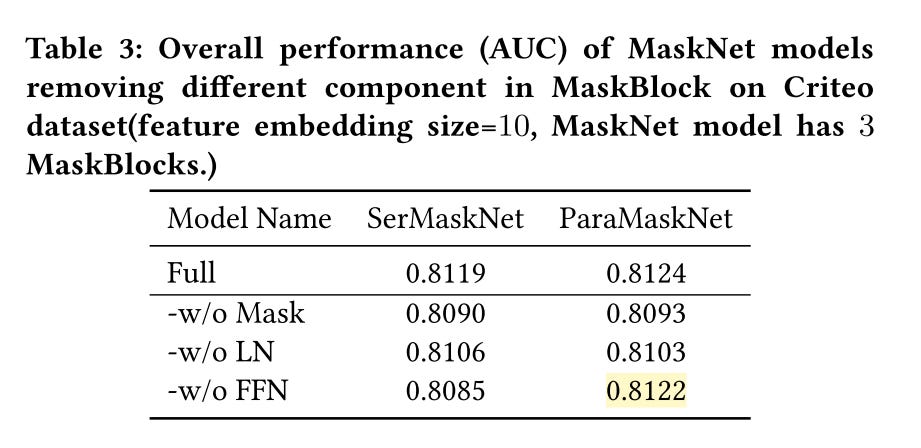
Ablation Study of MaskBlock
Removing either instance-guided mask or layer normalization will decrease the model’s performance
The serial model’s performance dramatically degrades, while it seems to do no harm to the parallel model if we remove the feed-forward layer in MaskBlock. This is like there are no dense layers, only feature masking
The feed-forward layer in MaskBlock is important for merging the feature interaction information after the instance-guided mask
Hyper-parameter Study
Some highlights:
Embedding size can help performance within a certain threshold
More MaskBlocks can always help parallel MaskNet, but not the same as serial MaskNet
The reduction ratio doesn’t affect the result much

Instance-guided Mask Study
Observe the output of the instance-guided mask:
The distribution of mask values follows the normal distribution. Over 50% of the mask values are small numbers near zero, and only little fraction of the mask values is a relatively larger number. My comment🤔: they should also compare the result to the distribution of the output of a standard feed-forward layer without masking. Is it possible that their output also follows the normal distribution?
Secondly, they randomly sample two instances and compare the difference of the produced values by instance-guided mask
The mask of the first instance pays more attention to the first few features
And they observe similar trends in the feed-forward layer? My comment🤔: I cannot see this in the second picture…And two instances cannot prove anything. They should at least sample multiple rounds

Show Me the Code
I implemented the MaskNet model in TensorFlow 2. Here is the link and the reference code in TensorFlow 1.
The instance-guided mask module:

The MaskBlock, notice that the output dimension for the instance-guided mask is dynamically inferred from the hidden_emb_shape, which could be either the feature embedding or the output of the previous MaskBlock.

And the last part, MaskNet. For the serial mode, the current MaskBlock output will become the next MaskBlock's input. Here, it’s the hidden_emb.

Run a basic example on Movielens 1M dataset, and the performances are close. This is just for a code check. I will test it on a larger dataset like Criteo later.

My Final Words
This paper is simple, and we can see that their ideas come from the attention module or other ranking models like DCN. But the overall design is too intuitive without formal theoretic proof. And also, the experimental results are not convincing.
In a word, it’s worth trying in production but do not put too much hope on it.
Weekly Digest
How Instacart Ads Modularized Data Pipelines With Lakehouse Architecture and Spark. Delta lake is the future of enterprise data processing.

Some Intuition on Attention and the Transformer. What’s the big deal about attention?
Spotify Track Neural Recommender System. An impressive tutorial on how to apply GNN to Spotify Track recommendation
Some Neural Networks Learn Language Like Humans. Do NN models work like the human brain? Researchers uncover striking parallels in the ways that humans and machine learning models acquire language skills
Introducing the ChatGPT app for iOS. The iOS version is released with instant answers, tailored advice, creative inspiration, etc
Researchers use AI to identify similar materials in images. This is a fascinating topic. How to detect the same material in the image?



What’s Next
In the next post, let’s have a summarization of the whole recommendation system in Twitter. I will also look at their source code to know more details, especially the difference between the paper and the code.
I may also look at the TwHIN3, Embedding the Twitter Heterogeneous Information
Network for Personalized Recommendation.
https://arxiv.org/pdf/2102.07619.pdf
https://arxiv.org/pdf/2008.13535.pdf
https://arxiv.org/pdf/2202.05387.pdf