

Dive into Twitter's recommendation system VI - Summary
Dive into Twitter's recommendation system VI - Summary
The TwHIN paper and the system implementation

This will be the final post of sharing on Twitter’s recommendation system. For the previous posts, please refer to:





TwHIN
As I shared in the last post, let’s read the TwHIN paper1 - Embedding the Twitter Heterogeneous Information Network for Personalized Recommendation. The code is here.
What is TwHIN?
In short, TwHIN leverages the Knowledge Graph approach, aka TransE, to learn embedding representations for various Twitter entities (e.g., user, content, advertiser, etc.) and entity interactions (e.g., a user re-sharing content or “following” another).
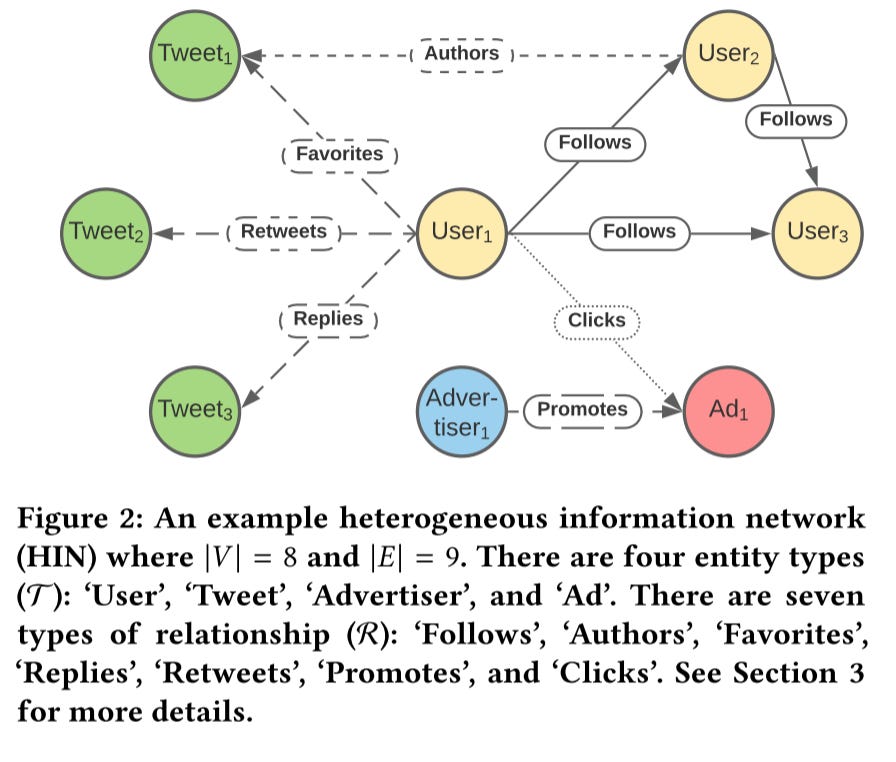
Compared to traditional HINs like Pinsage, which only includes the user, pins, and their click or repin interactions, TwHIN is a multi-type multi-relational network.
TwHIN capture signals such as social signals (follow-graph), content engagement signals (Tweet, image, and video engagement), advertisement engagements, and others to learn embeddings for users, tweets, and advertisements, and other types
It’s trained on only a single multi-GPU machine
It mitigates the data sparse issue by co-embedding the high-coverage relations like User-follow and User-Tweet graphs, with low-coverage relations such as promoted Tweets (Advertisements), advertisers, and promoted mobile apps. Notice that these two high-coverage graphs are trained separately with the low-coverage graphs
At last, the HIN embeddings provide utility as features in downstream recommendation tasks
How to learn embeddings?
Translating embeddings (TransE) is applied to learn to embed entities and edges in a HIN. TransE is a straightforward method to capture the node relationships using vector addition and inner product operations.

For an edge 𝑒 = (𝑠, 𝑟, 𝑡), this operation is defined by:
θ is the embedding parameters
s is the source node, r is the edge, t is the target node
The goal is the make the s + r as close as possible to positive t and as far as possible from negative t.
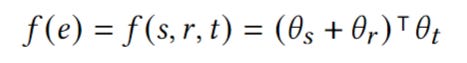
The loss is an NCE loss. The negative edges are sampled by corrupting positive edges via replacing either the source or target entity in a triple with a negatively sampled entity of the same entity type. And the negative sampling is performed both uniformly and proportional to entity prevalence in training (down weight popular samples).

Multi-modal Embeddings
Single embedding is not enough:
It cannot capture complex user behaviors and interests
It also can’t easily support out-of-vocabulary nodes, which is especially bad for fast-evolving tweets and users
To solve this issue, they
use k-means to cluster existing unimodal embeddings (all the target nodes)
compute multiple embeddings for a node by aggregating the most engaged-with clusters for a node. And associate each user Ui with a probability distribution over elements of 𝐶 proportional to the amount of engagement the user has with each cluster
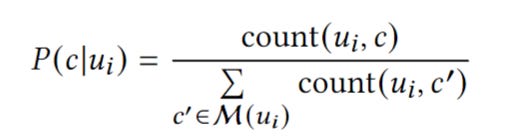
count(u𝑖 , 𝑐) is the number of times 𝑢𝑖 engages with a target in cluster 𝑐
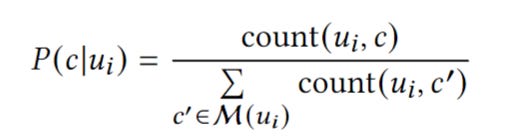
Application
The multi-modal embeddings are applied to:
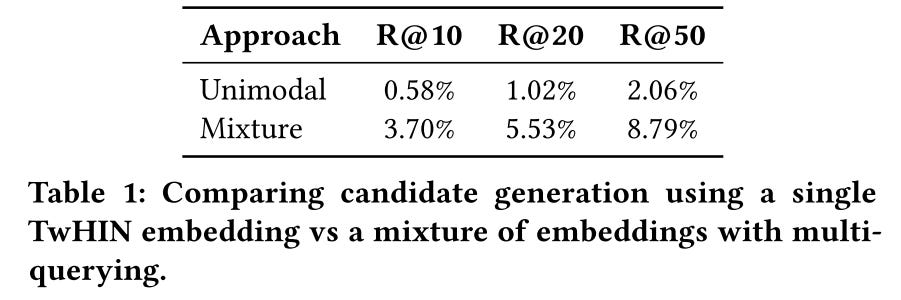
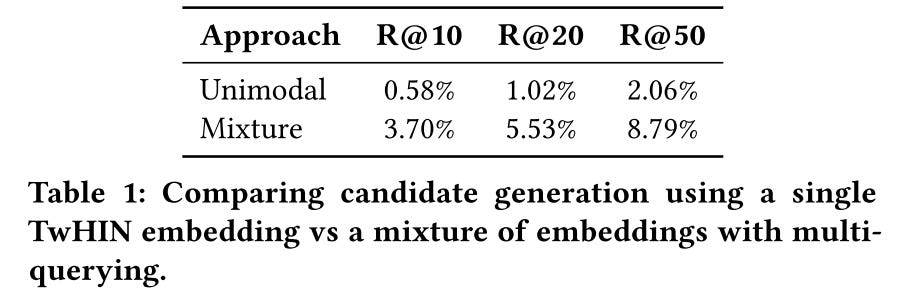
Candidate generation for Who-to-follow, retrieve candidates based on each embedding, and then mix the candidates together proportional to the weights defined above. Multi-modal embeddings work four times better than uni-modal embedding
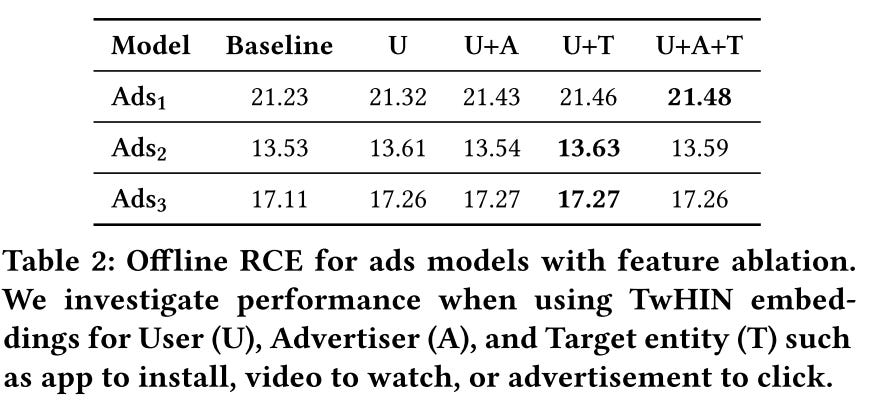
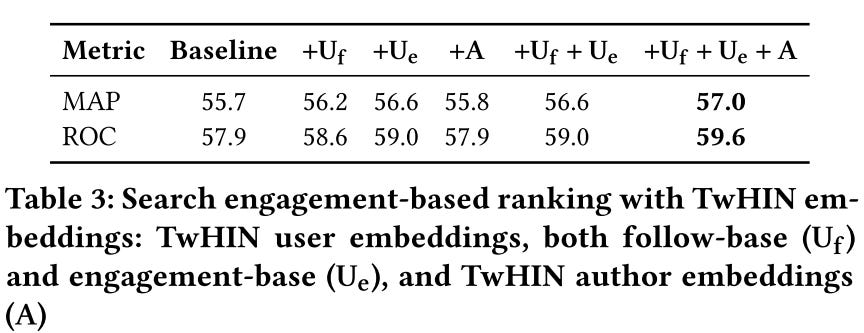
Feature for ads ranking and search ranking. Both have significant offline metrics gain. Notice that user embeddings contribute much more than other entity embeddings

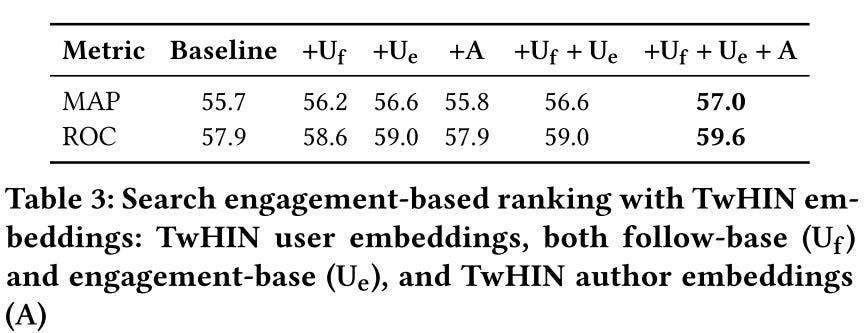
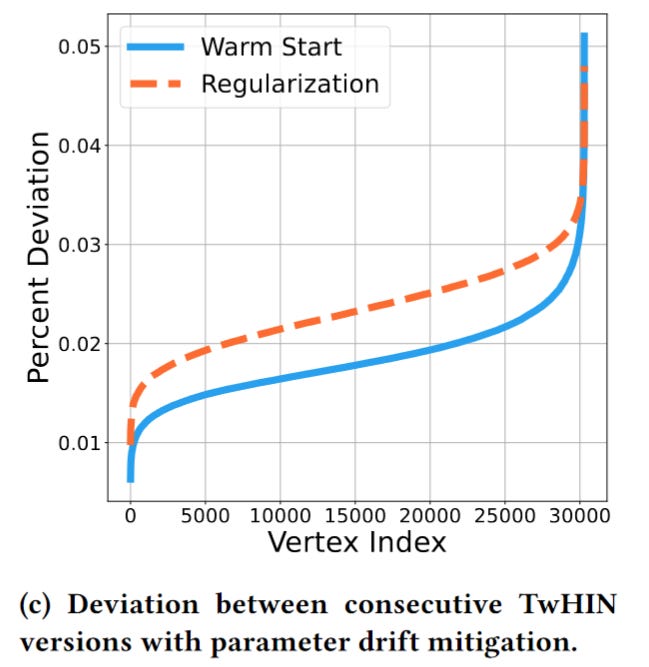
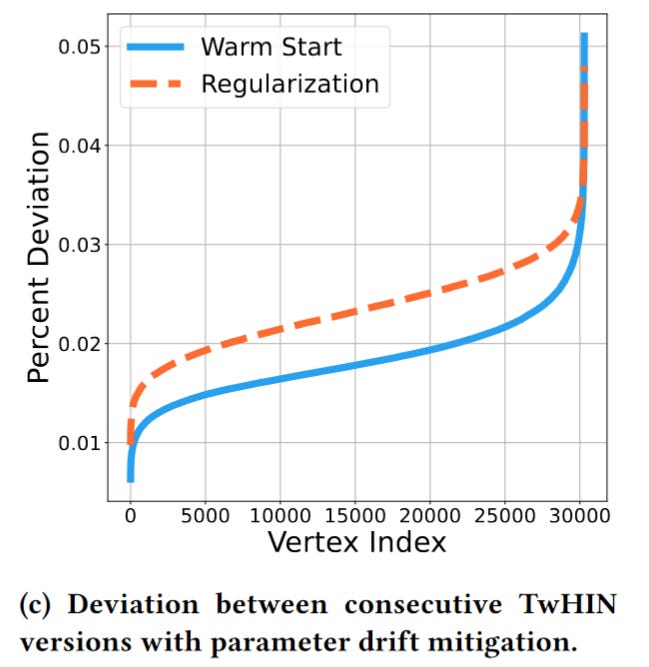
Addressing parameter drift across versions
Because downstream models use the TwHIN embeddings as features, the stability of embeddings is critical. We can’t re-train all the downstream models whenever the embedding parameter shift.
How to mitigate the embedding parameter shift when re-training?
Two methods are applied:
warm start: initialize the embeddings with the previous version value
regularization: directly penalize divergence from a past version using an L2 regularizer

In practice, they finally only use the wam start method because the L2 method requires loading the previous embedding, which will double the memory requirement. And the performances are similar
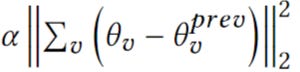
That’s all for TwHIN. 🎯
The System Implementation
I went through the code base of Twitter’s algorithm. It’s actually quite messy. There are many legacy codes, and many services are highly coupled to each other. The actual data flow differs from what they shared in the GitHub repo or their blog. Let’s focus on the home feed ranking system part.
The core components are listed below:
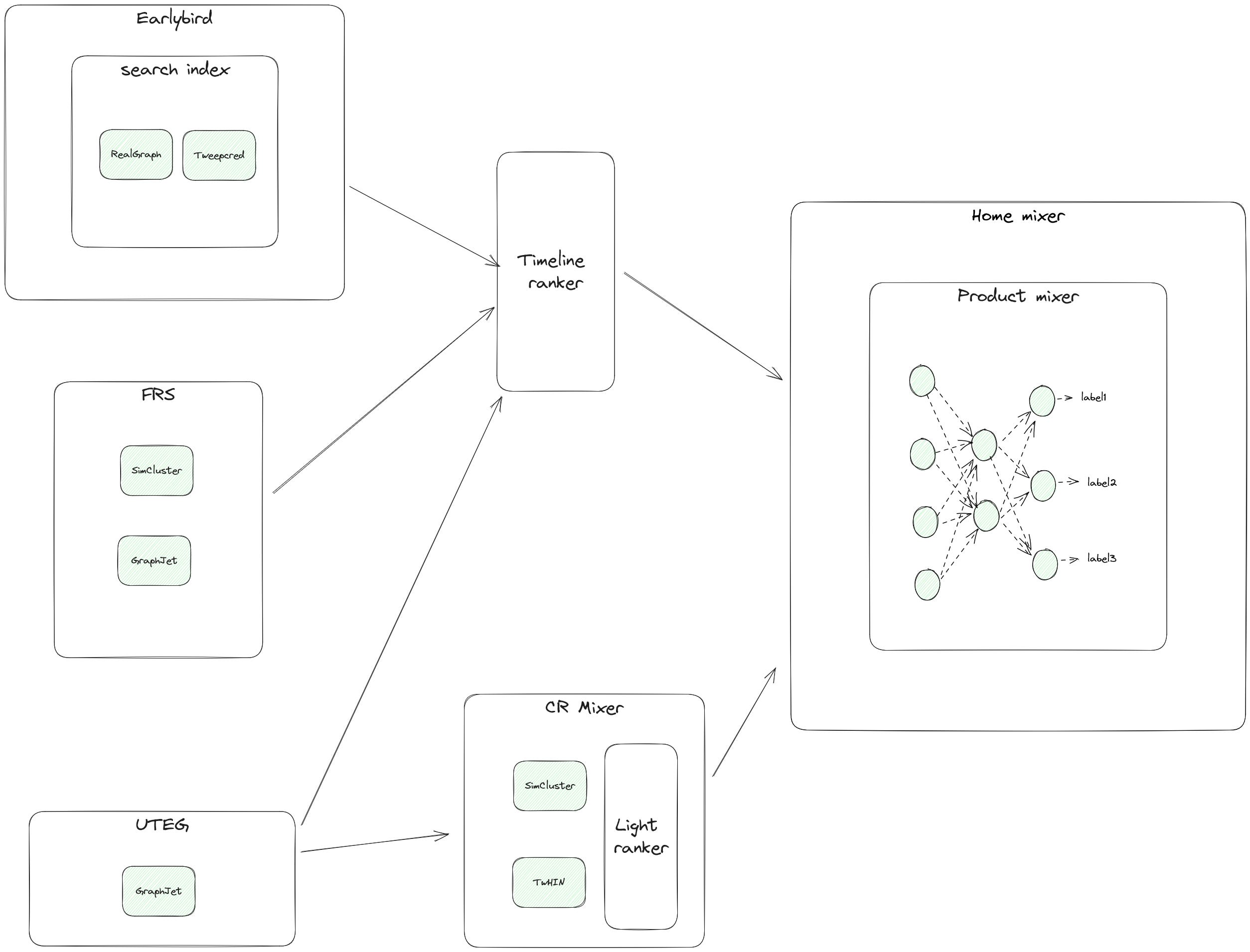
Home-mixer is the core online service. The common modules are defined in product-mixer
The timeline ranker is a legacy service. Now it acts mainly as a proxy to forward requests to the final services
Earlybird is the primary search index service, and it supports efficiently retrieving tweets from a set of users, like people you follow. Compared to GraphJet:
We can take GraphJet as a simplified version of Earlybird. Actually, GraphJet borrows many ideas from Earlybird
GraphJet only stores the basic user tweets information and their interactions. And the whole graph is stored in a single machine other than the distributed system in Earlybird
GraphJet only supported limited operations
GraphJet has a built-in recommendation engine to generate candidates for a specific user
FRS is the follow recommendation service that provides users with personalized suggestions for accounts to follow (Who-To-Follow)
CR-Mixer is a candidate generation service. It acts as a lightweight coordinating layer that delegates candidate generation tasks to underlying computing services
The overall ranking pipeline is defined here
The heavy ranker is a MaskNet-based multi-task model trained here
The outputs of the model are combined into a final model score by doing a weighted sum across the predicted engagement probabilities
The label mixture weights are defined here
The light ranker is a legacy TF1.0 model, not been maintained for years.
The candidate sources are defined here.
For the CR-mixer source, it calls the getTweetRecommendations API in the CR-mixer service. The corresponding implementation is here. It finally calls the CrCandidateGenerator class
For the in-network source, it calls the getRecycledTweetCandidates in the timeline-ranker service. On the timeline-ranker service side, it get the results from inNetworkTweetRepository. Then finally, the request is passed to the Earlybird or other services
For the UTEG source, it calls the getUtegLikedByTweetCandidates in the timeline-ranker service. And the request is finally passed to UTEG service
For the FRS source, it calls the getRecapCandidatesFromAuthors in the timeline-ranker service. And the request is finally passed to the Earlybird service
The RealGraph is used:
in the TweepCred service, as the initial weight for running the page rank algorithm. TweepCred builds the circle of trust for a specific user
in the CR-Mixer service, as the seeds to retrieve tweets from the UTEG service
in the timeline-ranker service, to expand the seed users
in the FRS service, as a candidate source
The GraphJet (UTEG) is used:
as the candidate source in timeline-ranker and CR mixer service
The SimCluster is used:
The TwHIN is used:
Let’s stop here. The code is quite bad from my personal perspective. There are too many legacy codes and services. Not worth putting too much effort into reading them one line by one line. Knowing the overall picture is good enough.
We can see that Twitter is constantly improving its algorithm:
RealGraph - User follow action prediction using LR
GraphJet - User tweet interaction prediction using PageRank liked algorithm on Graph
SimClusters - User user/tweet interaction prediction using MF liked algorithm on Graph. The initial usage of embedding begins here
TwHIN - Multi-type and multi-relation embedding learning using TransE on Graph. Build a universal system to generate embeddings for all kinds of entities and relations
Weekly Digest
Not much update this week. People are enjoying the long week.😆
All the Hard Stuff Nobody Talks About when Building Products with LLMs. A practical guide on the obstacles of build products on LLMs
Large Language Models: A Complete Guide. Looks like a good index of LLM techniques
What’s Next
In the next post, I will go back and revisit classic recommendation papers again. See you.
https://arxiv.org/pdf/2202.05387.pdf